
이번에는 Amazon Quicksight를 사용하여 S3에 수집, 저장된 데이터에 대해 몇 가지 시각화를 구축할 것입니다.
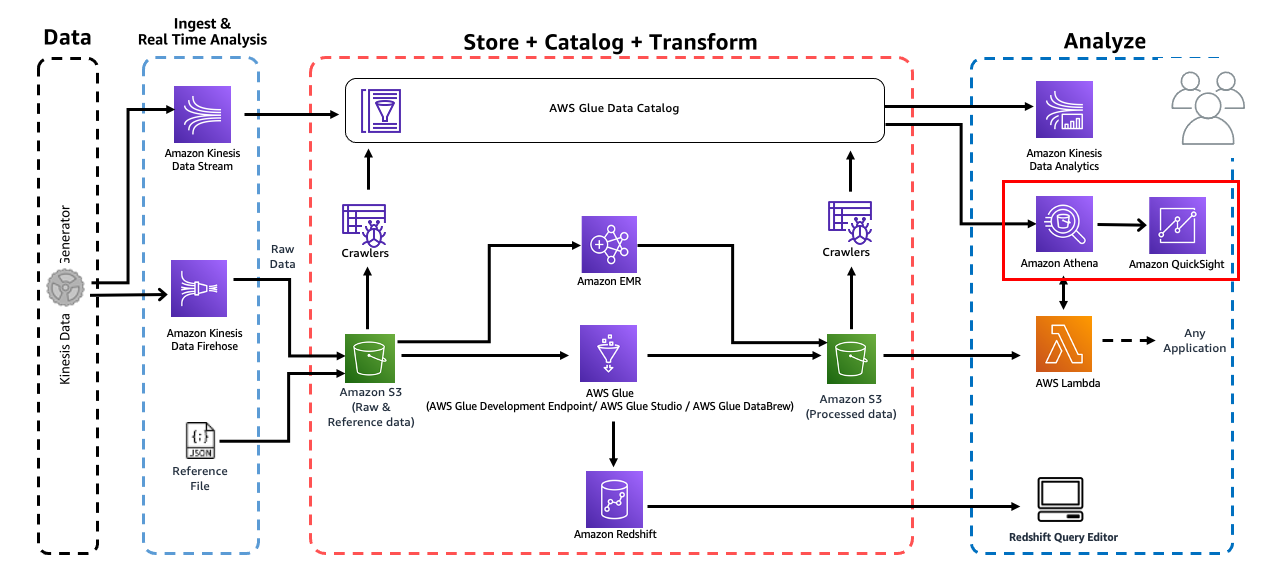
1. QuickSight 셋팅
이 단계에서는 QuickSight를 사용하여 processsed data를 시각화합니다.
먼저 Quicksight 콘솔 https://us-east-1.quicksight.aws.amazon.com/sn/start로 이동합니다. AWS에 로그인이 되어 있고 Quicksight 계정이 없는 상태라면 Sign up for QuickSight 버튼을 볼 수 있습니다. 클릭합니다.
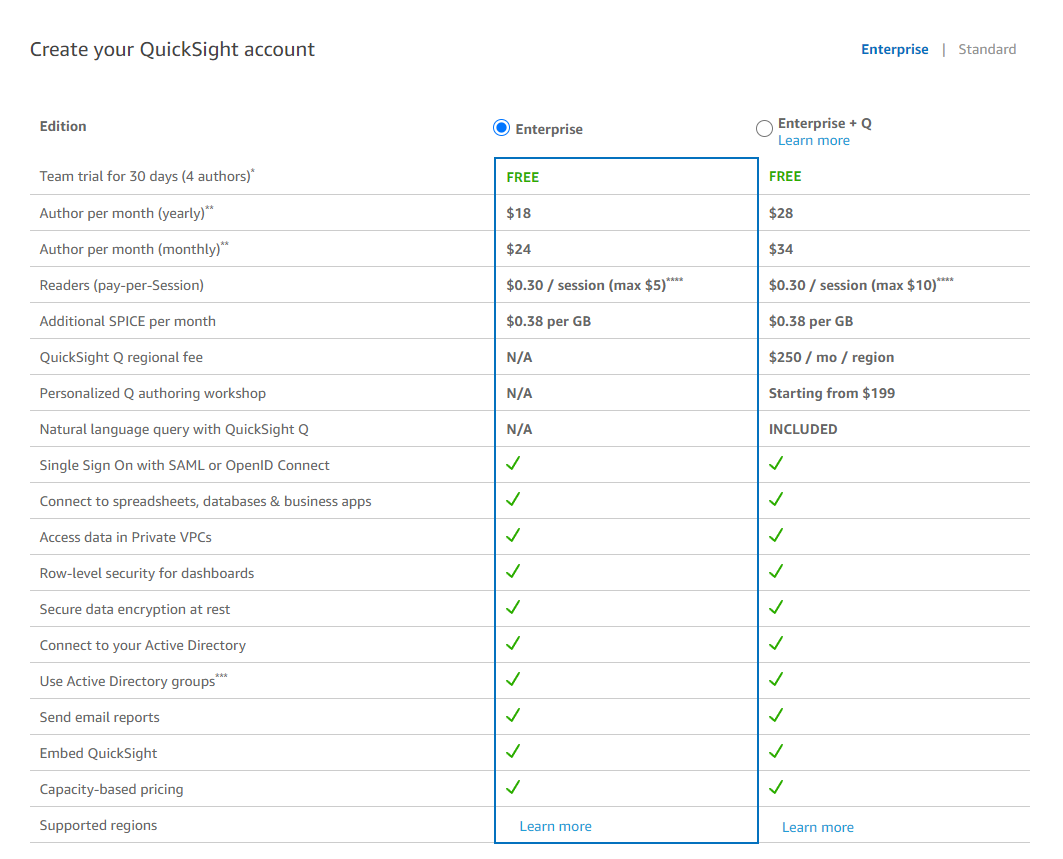
Enterprise를 선택하고 Continue 버튼을 누릅니다.
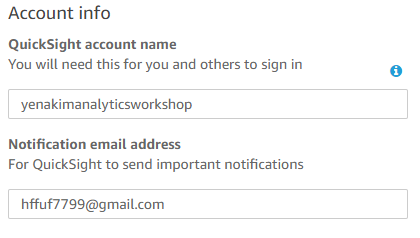
나머지는 기본 설정 그대로 두고 account name은 yournameanalyticsworkshop로, Notification email address는 본인의 이메일을 입력합니다.

이 부분에서는 Amazon S3와 Amazon Athena만 체크해 줍니다. Amazon S3에서는 yourname-analytics-workshop-bucket만 선택합니다. 여기까지 끝났으면 Finish를 클릭합니다.
2. 새로운 데이터세트 추가
https://us-east-1.quicksight.aws.amazon.com/sn/start/data-sets로 이동합니다.
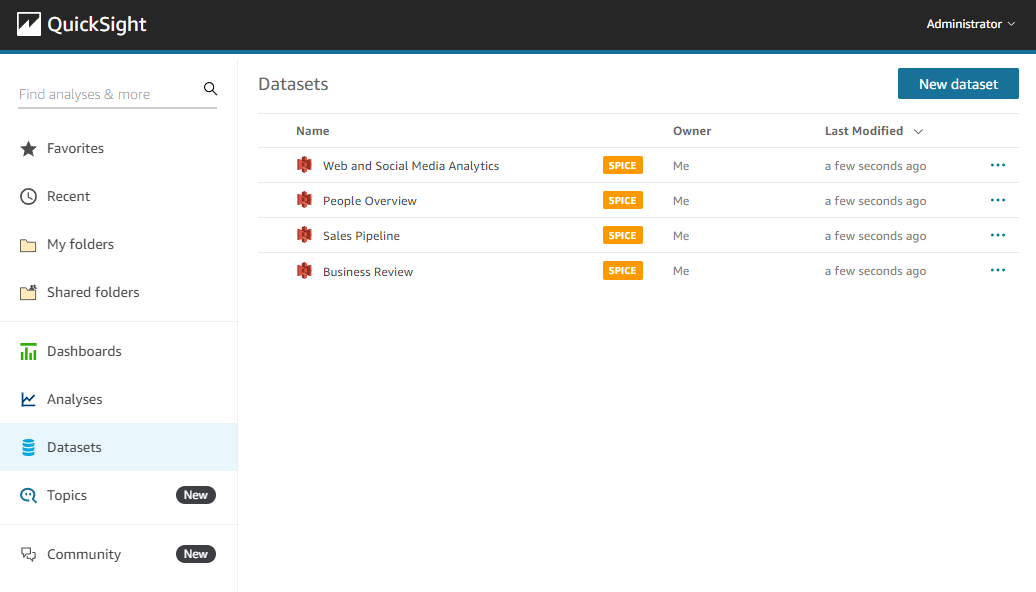
Datasets 탭으로 이동한 후 New dataset을 클릭합니다.

Athena를 클릭합니다.
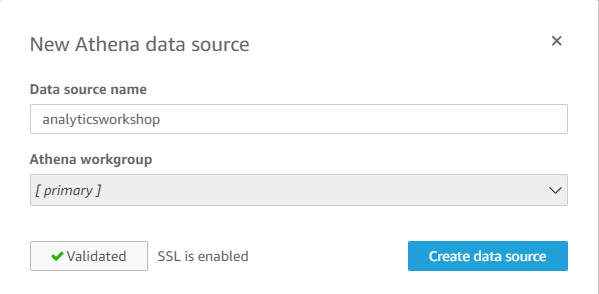
Data source name은 analyticsworkshop으로 하고, Validate connection을 클릭하여 위와 같이 Validated 상태로 만들어준 후 Create data source 버튼을 누릅니다.
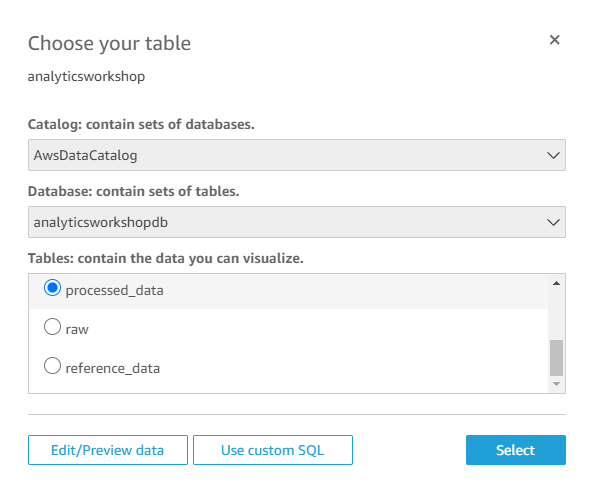
위와 동일하게 설정하고 Select를 클릭합니다.
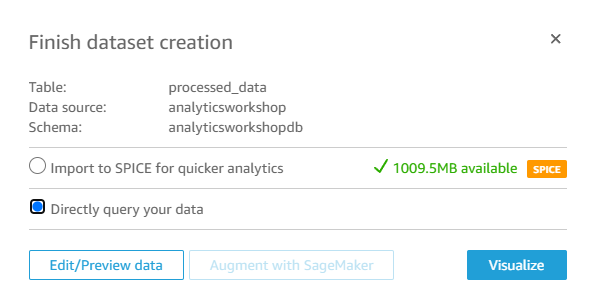
Directly quert your data를 선택하고 Visualize를 누릅니다.
3. Amazon Quicksight를 사용하여 processsed data 시각화
시각화 1 : 사용자가 듣고 있는 트랙의 히트맵
여기서는 어떤 사용자가 반복적으로 트랙을 듣고 있는지 보여주는 시각화를 합니다.
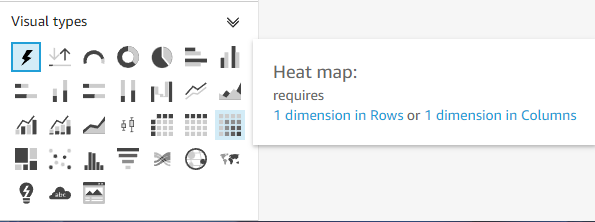
왼쪽 하단의 Visual types에서 Heat Map을 선택합니다.
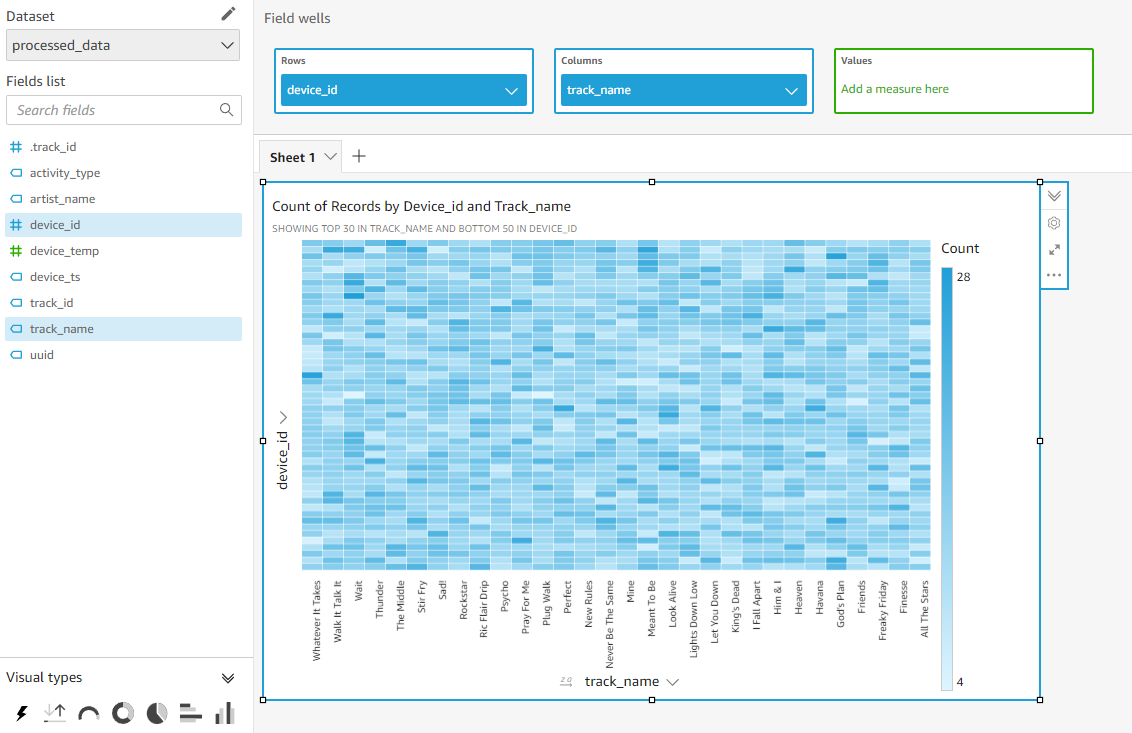
왼쪽 Fields list에서 device_id를 선택하고 track_name을 선택합니다. 위쪽에 있는 Field wells에 Rows: device_id, Columns: track_name가 표시되었다면 잘 설정된 것입니다.
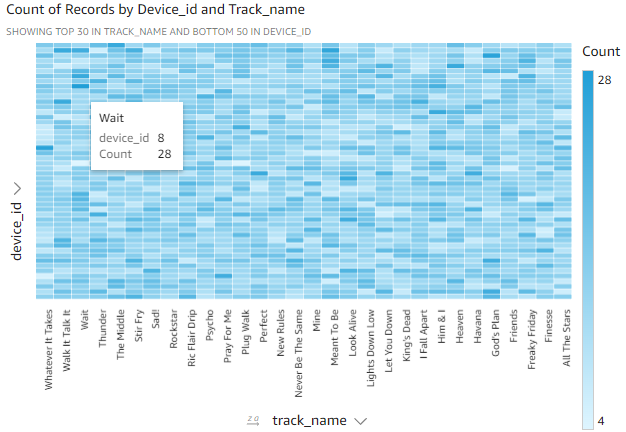
이처럼 진한 파란색 패치 위로 마우스를 가져가면 특정 사용자가 동일한 트랙을 반복적으로 듣고 있음을 알 수 있습니다.
시각화 2 : 가장 많이 연주 된 아티스트 이름의 트리맵
이 단계에서는 가장 많이 플레이 된 아티스트를 보여주는 시각화를 만듭니다.
왼쪽 상단 + Add 클릭 후에 Add Visual를 클릭합니다.

Visual types는 Tree Map을 클릭합니다.
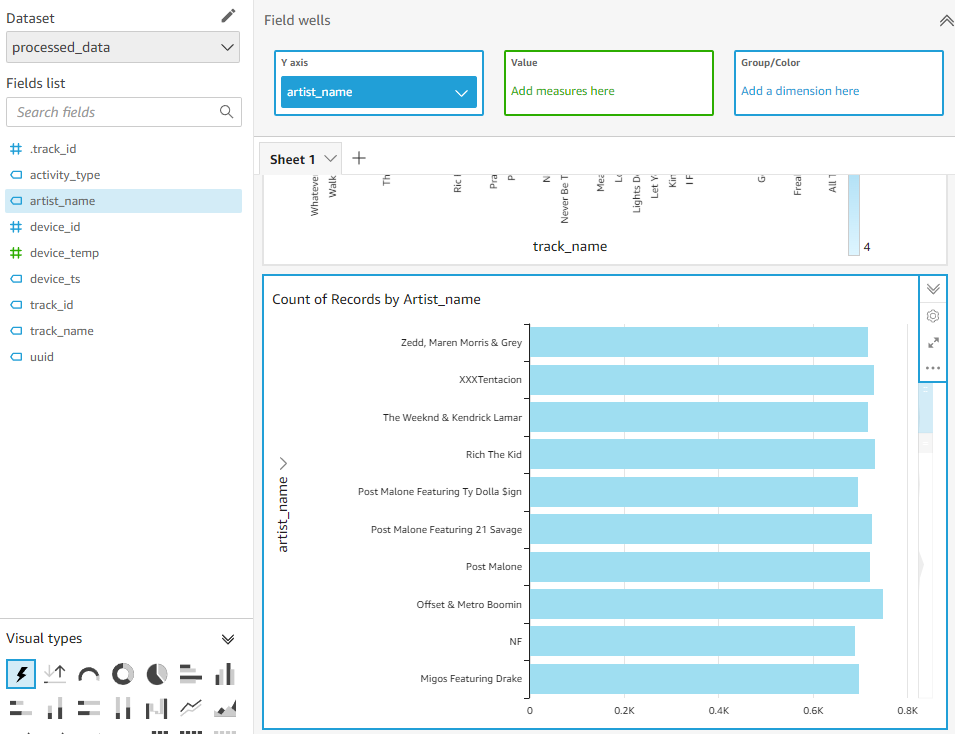
Fields list에서 artist_name을 선택하면 가장 많이 플레이 된 아티스트를 시각적으로 확인할 수 있습니다.