
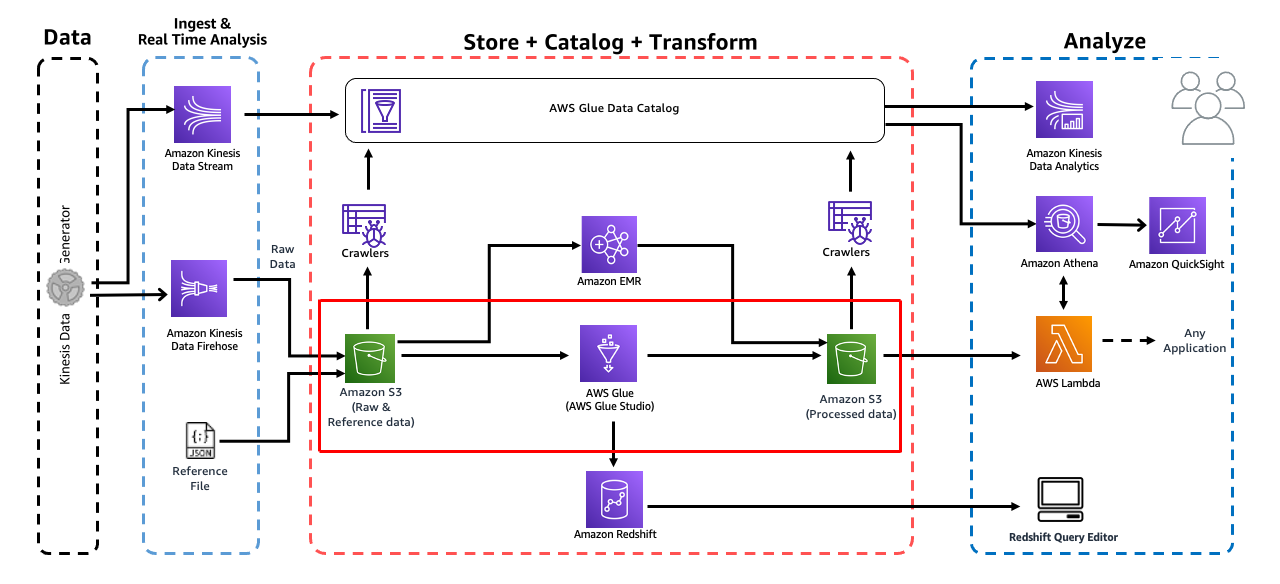
AWS Glue Studio는 AWS Glue에서 추출, 변환 및 로드(ETL) 작업을 쉽게 생성, 실행 및 모니터링 할 수 있는 새로운 그래픽 인터페이스 입니다. 데이터 변환 워크플로우를 시각적으로 구성하고 AWS Glue의 Apache Spark 기반 서버리스 ETL 엔진에서 원활하게 실행할 수 있습니다.
이 실습에서는 Transform Data with AWS Glue 와 동일한 ETL 프로세스를 수행합니다. 하지만 이번에는 AWS Glue Studio의 시각적 그래픽 인터페이스를 활용합니다.
먼저, Glue Studio 콘솔 https://us-east-1.console.aws.amazon.com/gluestudio/home?region=us-east-1#/로 이동합니다.
왼쪽 위 선 세 개를 눌러 메뉴를 확장한 후 Jobs를 클릭합니다.
Visual with a blank canvas를 선택하고 Create 버튼을 누릅니다.
Source 클릭 후 Amazon S3을 선택합니다.
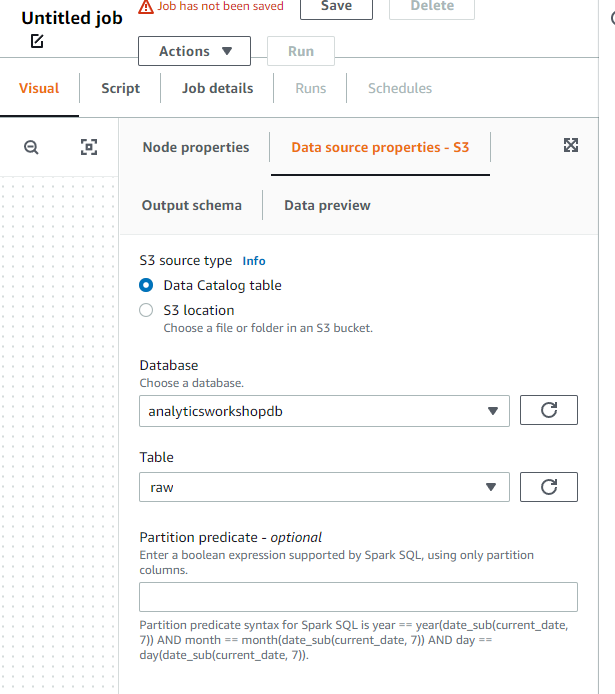
위와 동일하게 선택합니다.
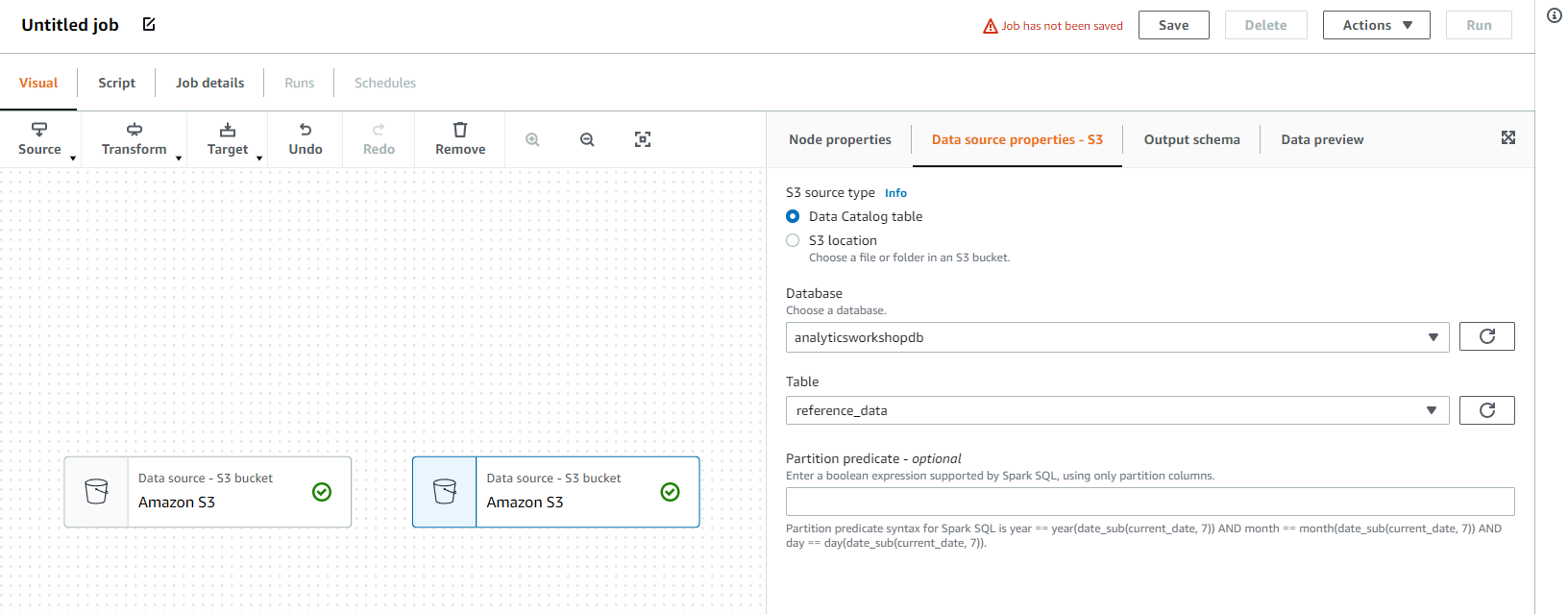
다시 Source 클릭 후 Amazon S3을 선택하고, raw만 reference_data로 바꾸어 추가합니다.
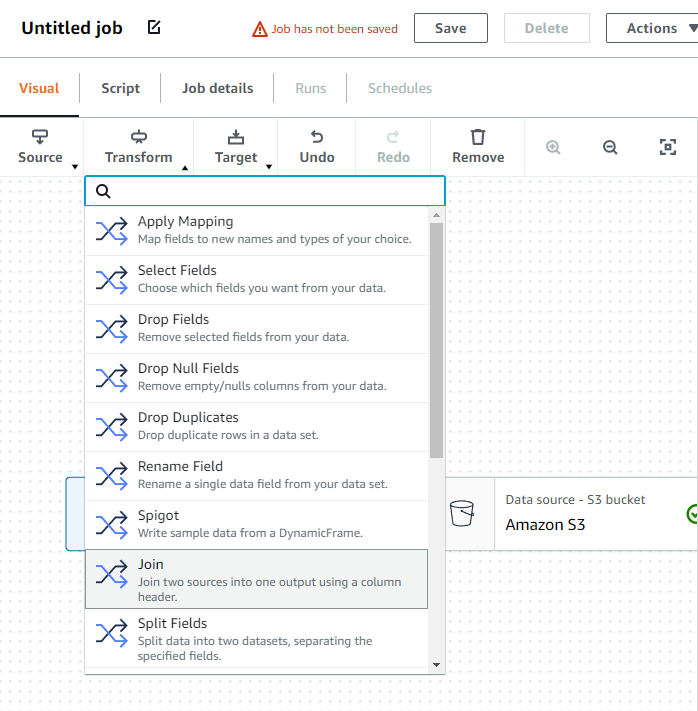
두 개 중 임의로 한 개를 클릭한 후 transform - join을 선택합니다.
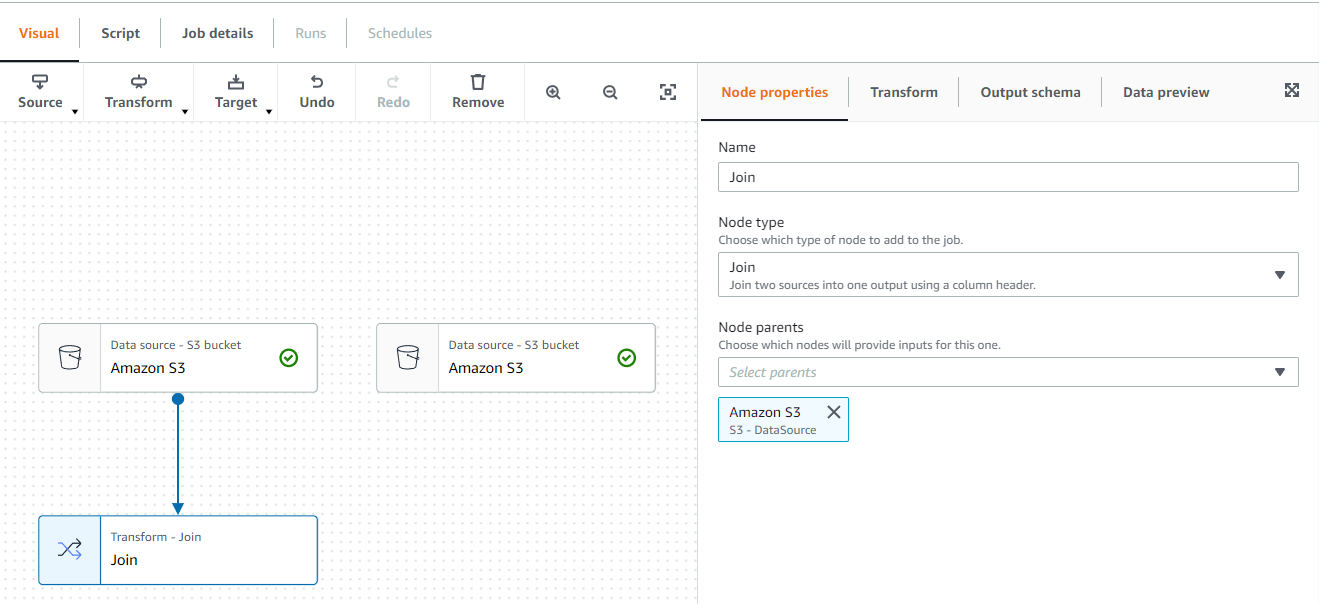
Transform에서 Node properties로 넘어갑니다.
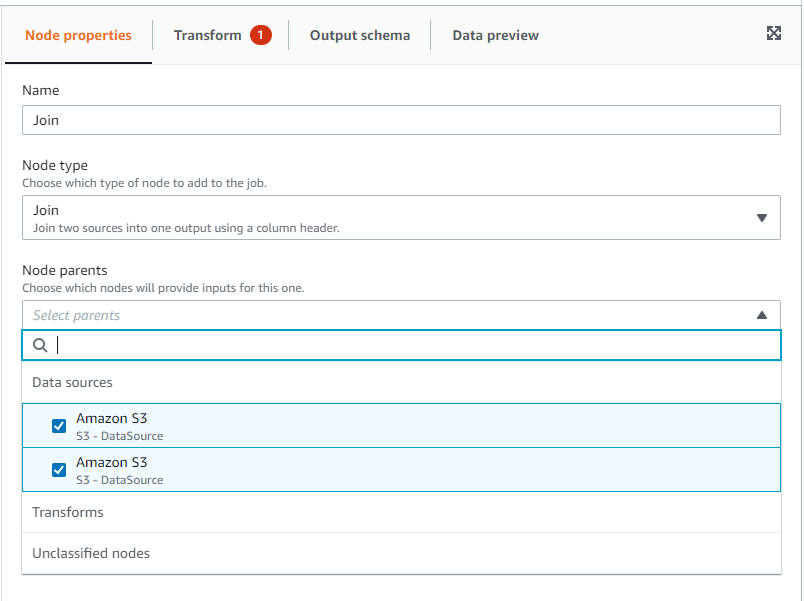
Node Parents에서 나머지 한 개도 선택합니다.
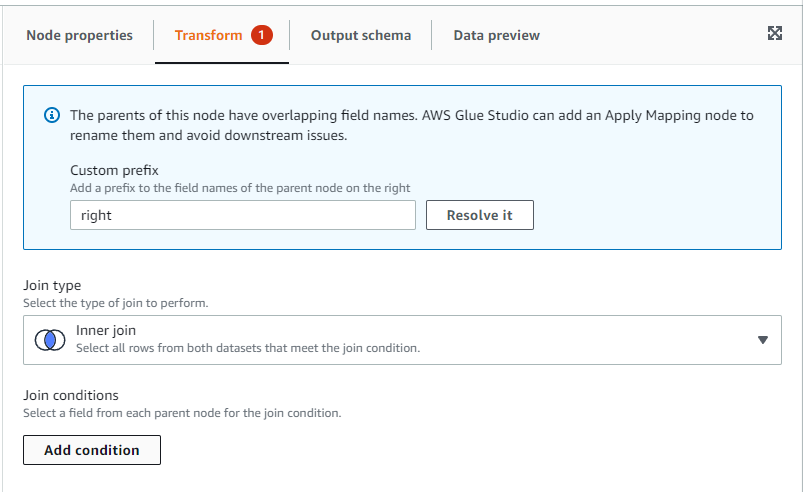
Transform 탭으로 넘어가 Add condition을 클릭합니다.
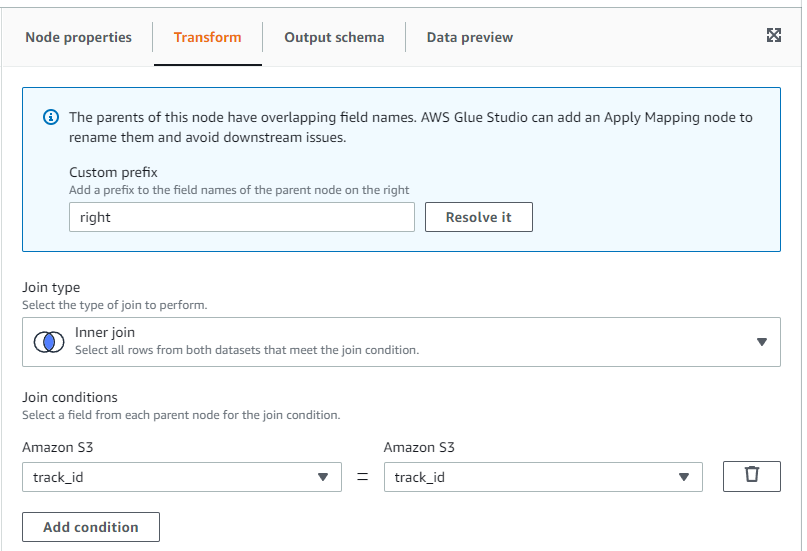
양쪽 모두 track_id를 선택합니다.
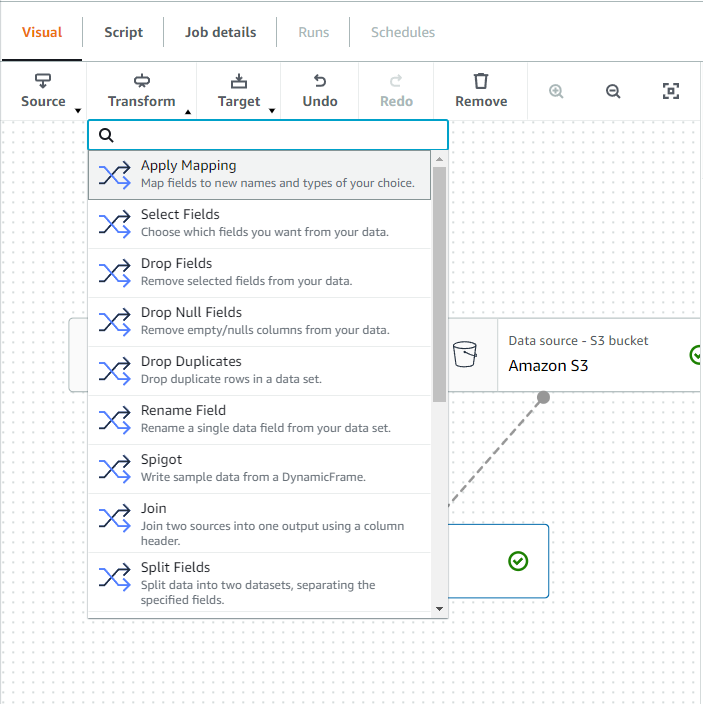
이제 원래 선택되어 있던 대로 두고(Join 노드 선택) Tramsform을 클릭하고 ApplyMapping을 선택합니다.
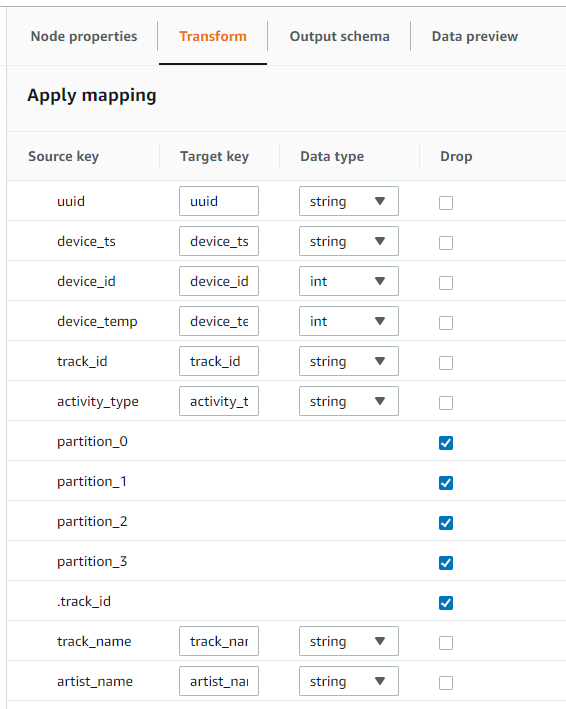
위와 같이 .track_id, parition_0, parition_1, parition_2, parition_3은 drop하고 track_id는 string으로 변경합니다.
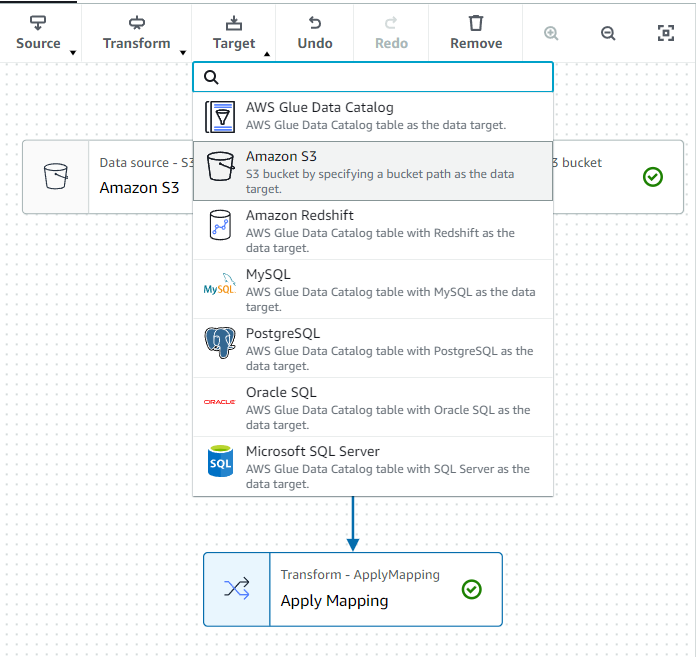
Target 클릭 후 S3를 선택합니다.
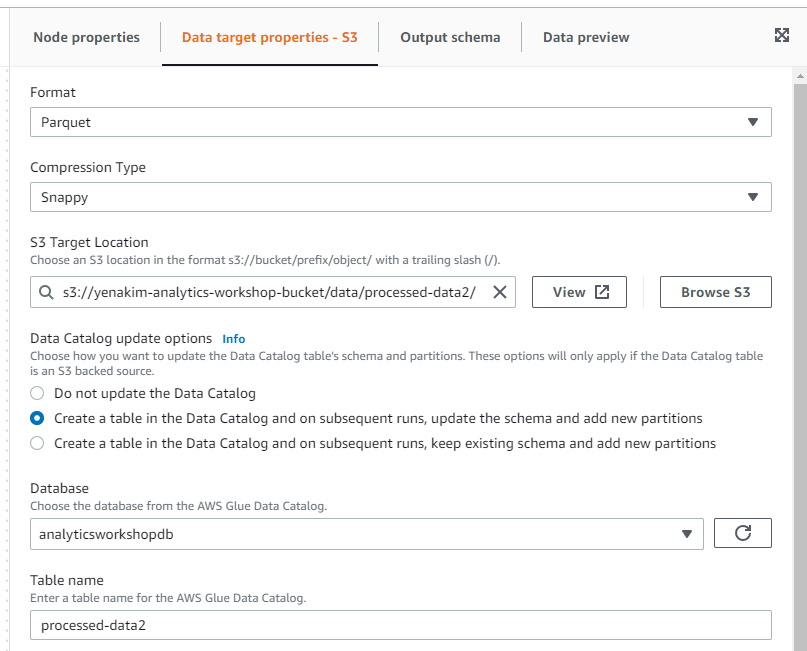
Data target properties - S3에 위과 같이 입력합니다. Format은 Parquet, Compression Type은 Snappy, S3 Target Location은 s3://yourname-analytics-workshop-bucket/data/processed-data2/(yourname은 본인 이름으로 변경), Data Catalog update options는 Create a table in the Data Catalog and on subsequent runs, update the schema and add new partitions를 선택하고 Database는 analyticsworkshopdb, Table name은 processed-data2로 합니다.
상단 Job details를 클릭합니다.
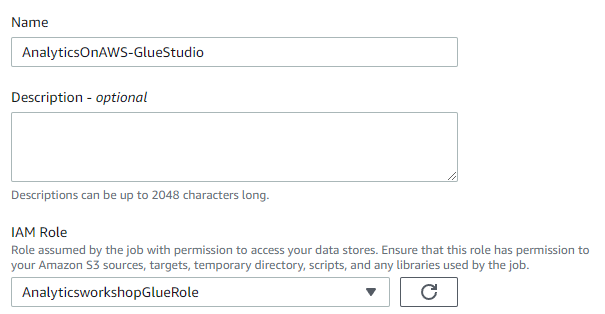
Name은 AnalyticsOnAWS-GlueStudio, IAM Role은 AnalyticsWorkshopGlueRole로 합니다.
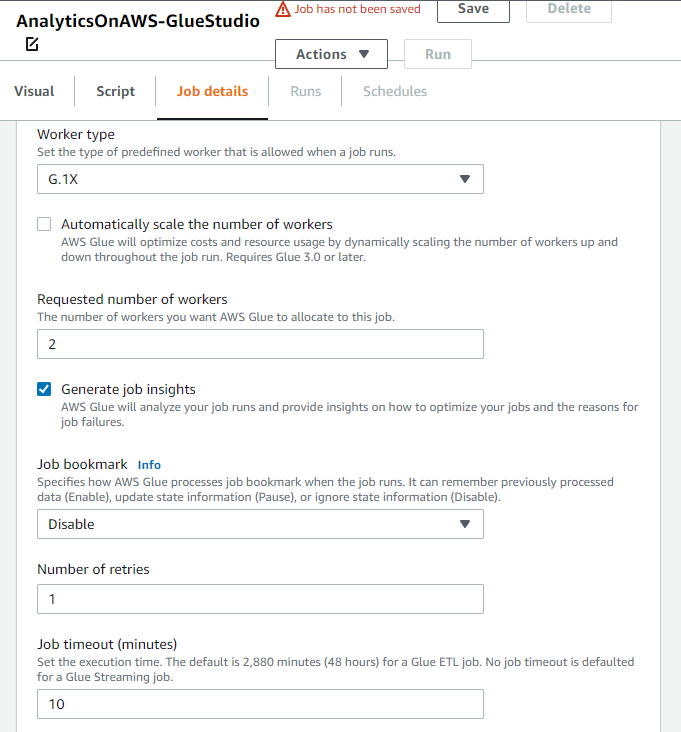
Number of workers는 2, Job bookmark는 Disable, Number of retries는 1, Job timeout는 10으로 설정하고 오른쪽 위에 있는 Save를 클릭합니다.
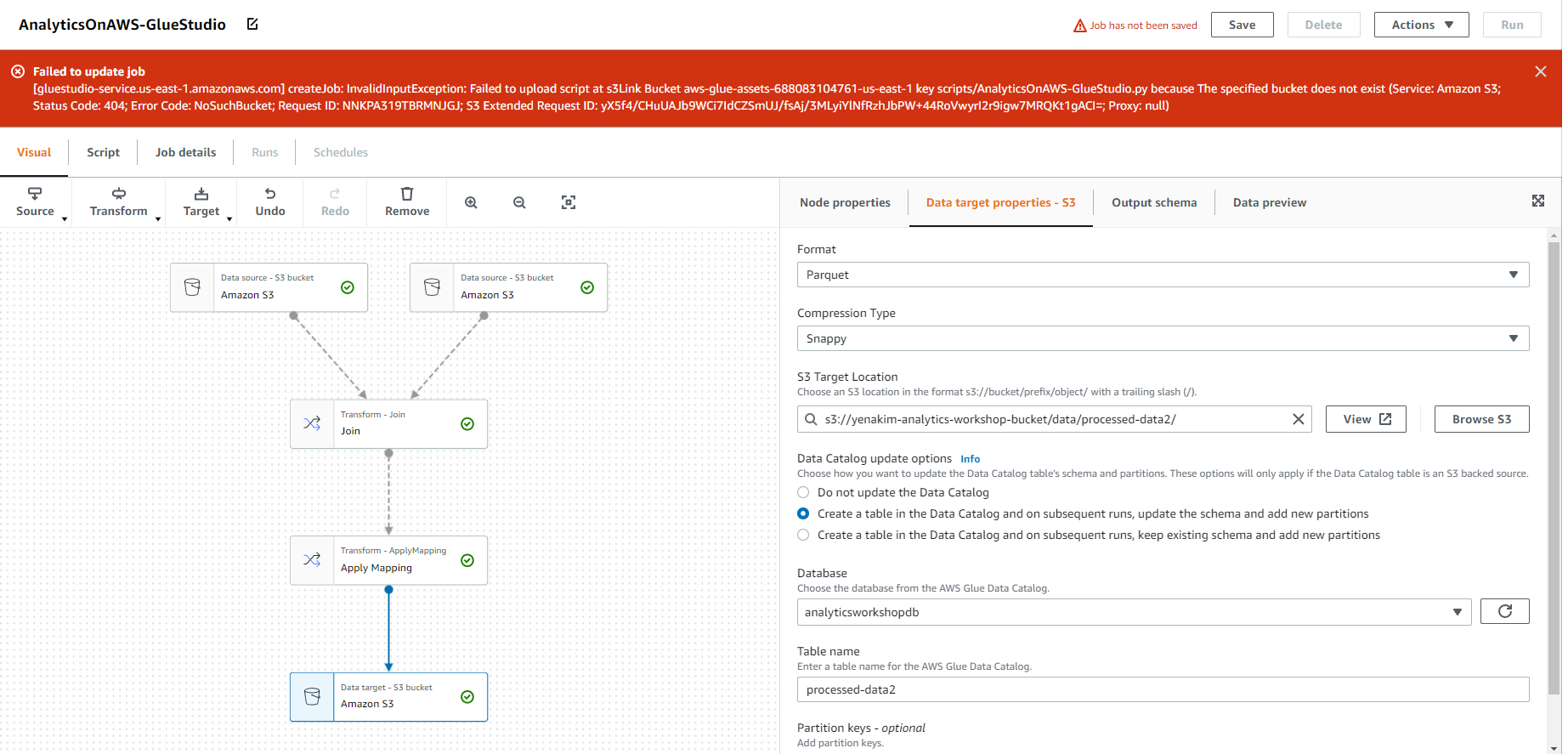
그런데 왜,,,Error가 떴는지 모르겠습니다. 다시 처음부터 해봐도 결과는 마찬가지… 해결하고 나서 추후 업데이트 하겠습니다.