
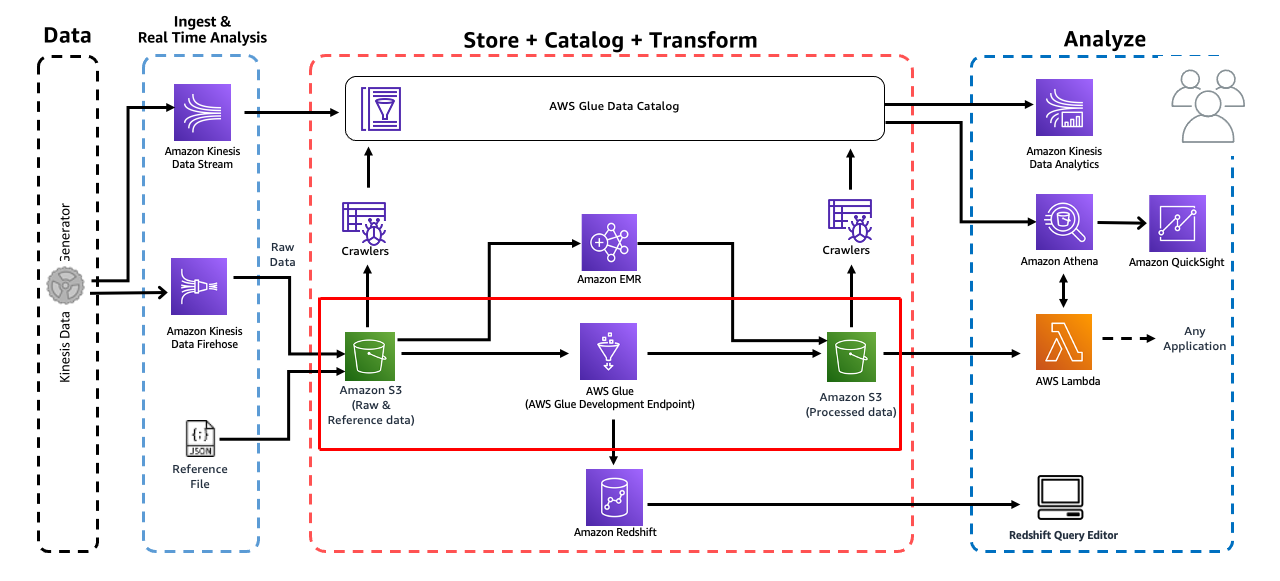
이 모듈에서는 AWS Glue ETL을 사용하여 데이터를 처리하고 결과를 다시 S3에 저장합니다. Glue 개발 엔드포인트와 Sagemaker 노트북을 사용하여 데이터 변환 단계를 진행합니다.
1. Glue 개발 엔드포인트 생성
이 단계에서는 PySpark를 사용하여 Glue ETL 스크립트를 대화식으로 개발하기 위해 AWS Glue Dev Endpoint를 생성합니다. Glue 개발 엔드포인트 콘솔 https://us-east-1.console.aws.amazon.com/glue/home?region=us-east-1#etl:tab=devEndpoints로 이동합시다.
엔드포인트 추가를 클릭합니다.
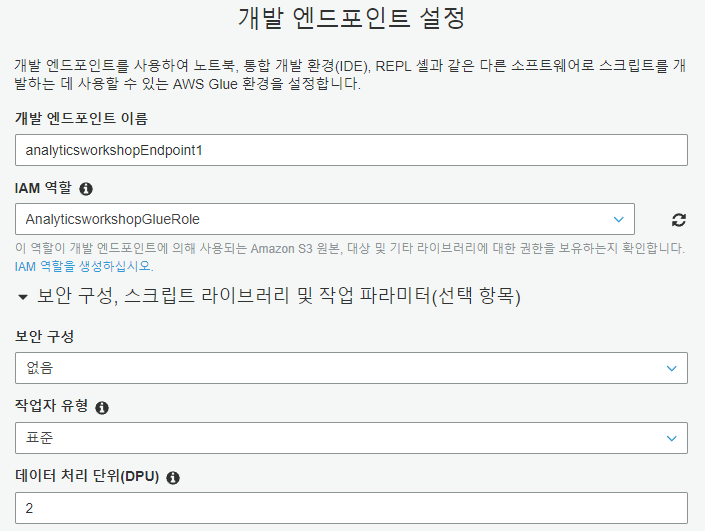
개발 엔드포인트 이름에는 analyticsworkshopEndpoint1, IAM 역할은 AnalyticsworkshopGlueRole, 데이터 처리 단위는 2로 설정하고 다음을 누릅니다.

네트워킹 정보 건너뛰기를 선택하고 다음을 누릅니다.
다음으로 나오는 SSH 퍼블릭 키 추가는 하지 않고 다음을 누릅니다.
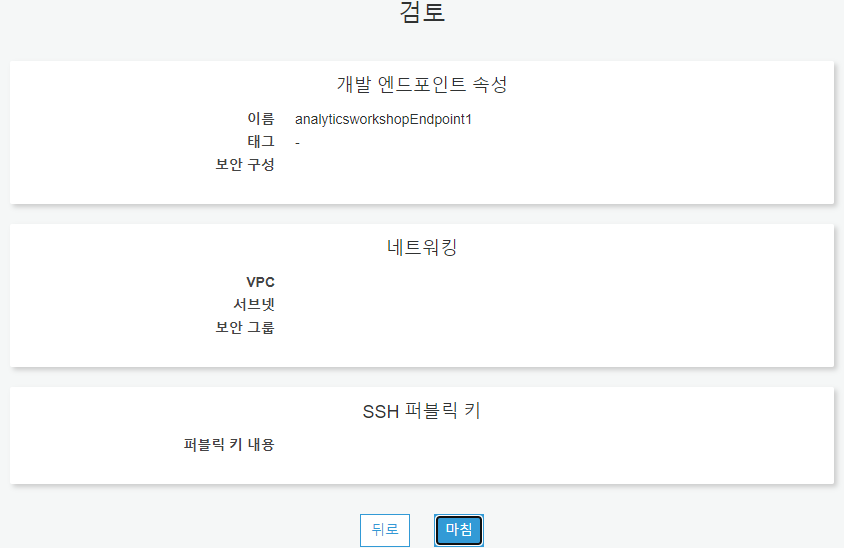
마지막으로 설정을 확인한 후 마침을 누릅니다. 새로운 Glue 개발 엔드포인트가 가동되면 상태가 PROVISIONING에서 READY으로 변경되는데 6 ~ 10분정도 기다려야 합니다.
2. Glue 개발 엔드포인트용 SageMaker 노트북 (Jupyter) 생성
노트북 콘솔 https://us-east-1.console.aws.amazon.com/glue/home?region=us-east-1#etl:tab=notebooks로 이동합니다.
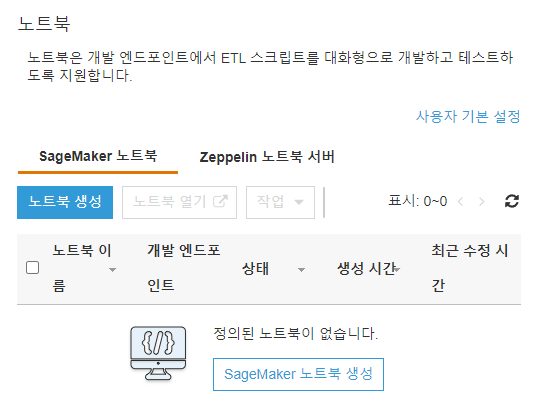
노트북 생성을 클릭합니다.
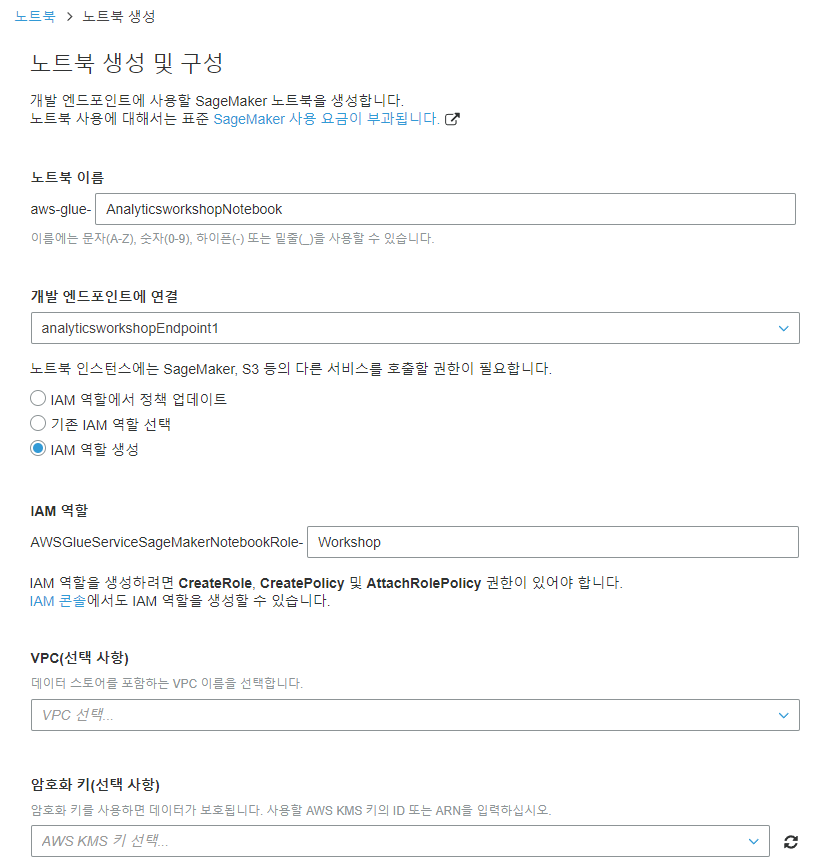
노트북 이름은 AnalyticsworkshopNotebook, 엔드포인트는 analyticsworkshopEndpoint1, IAM 역할 생성 선택, IAM 역할에는 Workshop을 입력하고 나머지 칸은 비운 후 노트북 생성을 클릭합니다.
4 ~ 5분 정도 소요됩니다. 노트북 생성 상태가 시작하는 중에서 Ready로 변경 될 때까지 기다립니다.
3. Jupyter 노트북 실행
https://static.us-east-1.prod.workshops.aws/public/b4ab4ec2-9ab1-4c41-bf19-964db5dcc495/static/notebooks/analytics-workshop-notebook.ipynb로 이동해 파일을 로컬로 다운로드하고 저장합니다.
다음으로 노트북 콘솔 https://us-east-1.console.aws.amazon.com/glue/home?region=us-east-1#etl:tab=notebooks로 이동합니다.

aws-glue-AnalyticsworkshopNotebook을 클릭합니다.(다시 보니 시작하는 중이라서 좀만 더 기다려 주겠습니다,,,)
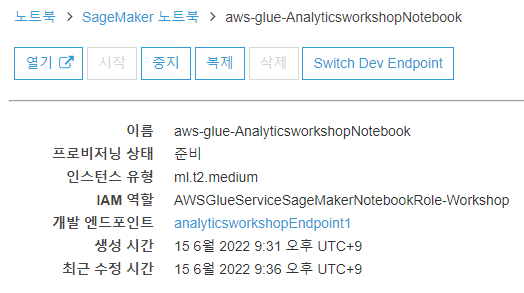
열기를 눌러줍니다.
요금이 부과된다고 합니다.

Sagemaker Jupyter 노트북에서 Upload를 누릅니다.
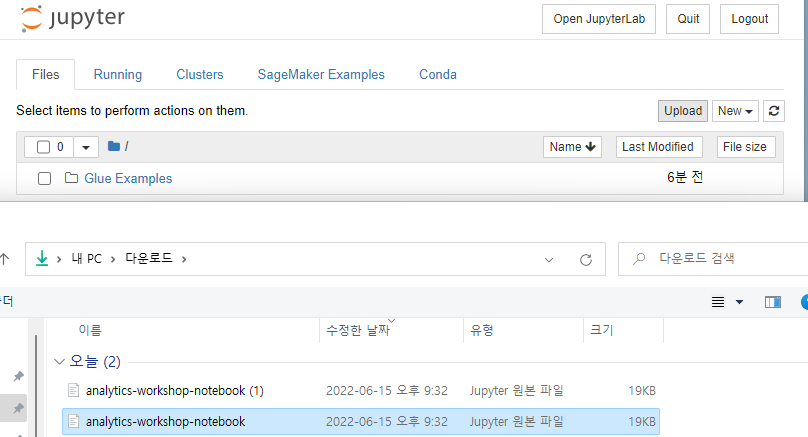
다운로드한 analytics-workshop-notebook.ipynb 파일을 찾은 후 업로드합니다.
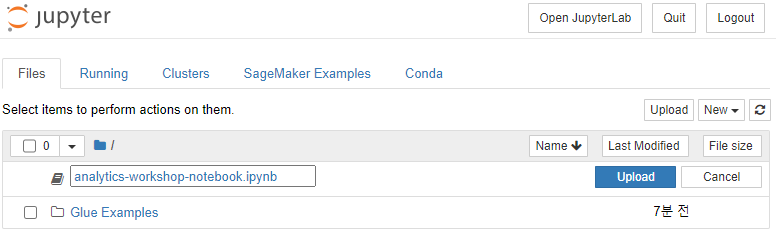
Upload를 클릭합니다.
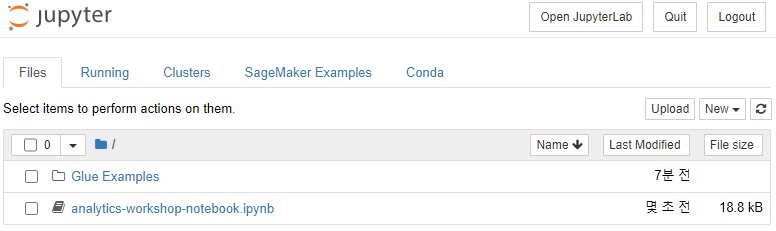
analytics-workshop-notebook.ipynb 노트북을 클릭하여 엽니다.
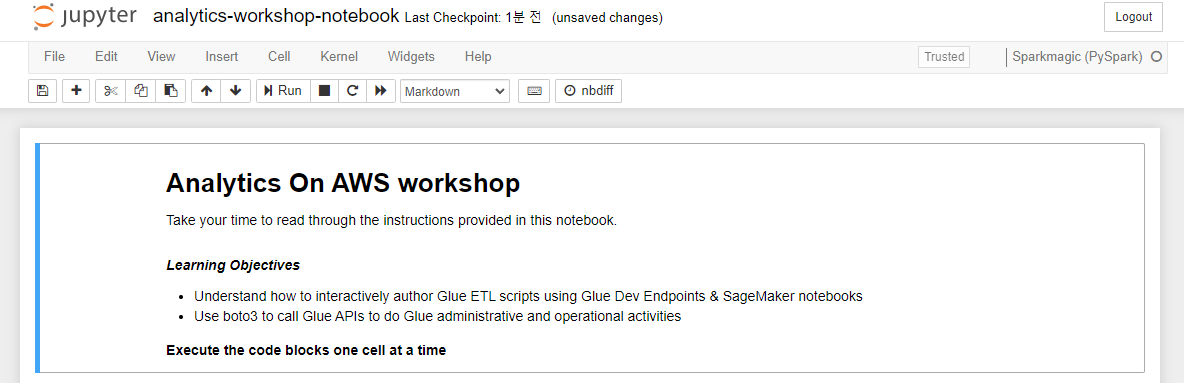
오른쪽 위에 Sparkmagic (PySpark)라고 표시되어 있는지 확인합니다. Jupyter가 이 노트북에서 코드 블록을 실행하는데 사용할 커널의 이름이라고 합니다.
이제 노트북의 지침을 읽고 차례로 실행해 봅시다.
Final step of the transform - Writing transformed data to S3 아래의 다음과 같은 코드에 yourname-analytics-workshop-bucket을 본인의 상황에 맞게 바꿉시다.
1
2
3
4
5
6
7
8
9
try:
datasink = glueContext.write_dynamic_frame.from_options(
frame = joined_data_clean, connection_type="s3",
connection_options = {"path": "s3://yenakim-analytics-workshop-bucket/data/processed-data/"},
format = "parquet")
print('Transformed data written to S3')
except Exception as ex:
print('Something went wrong')
print(ex)
4. 확인 - 가공/변경된 S3 데이터
ETL 스크립트가 성공적으로 실행되면 https://s3.console.aws.amazon.com/s3/buckets?region=us-east-1 콘솔로 돌아갑니다.
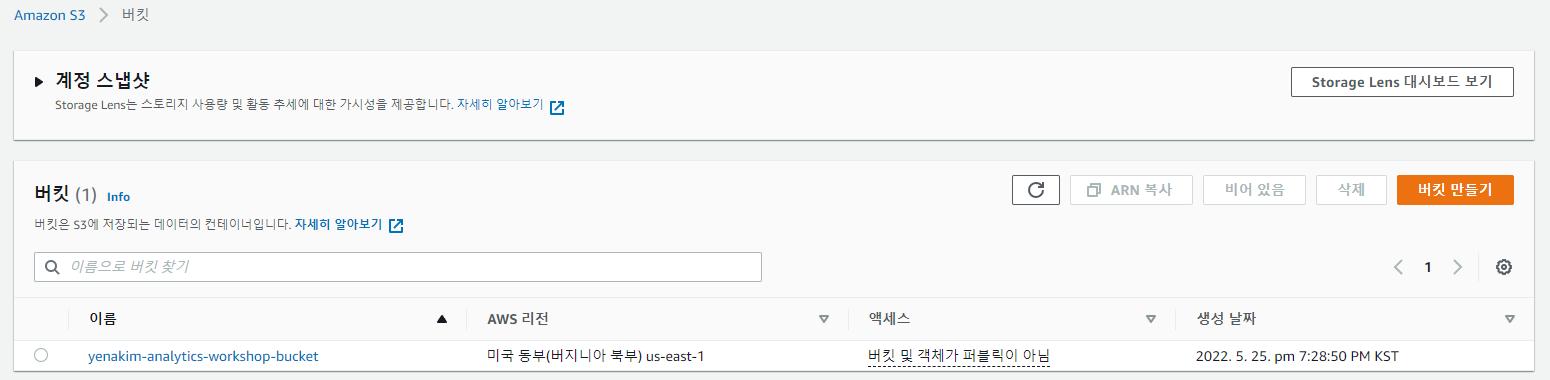
yourname-analytics-workshop-bucket으로 들어갑니다.
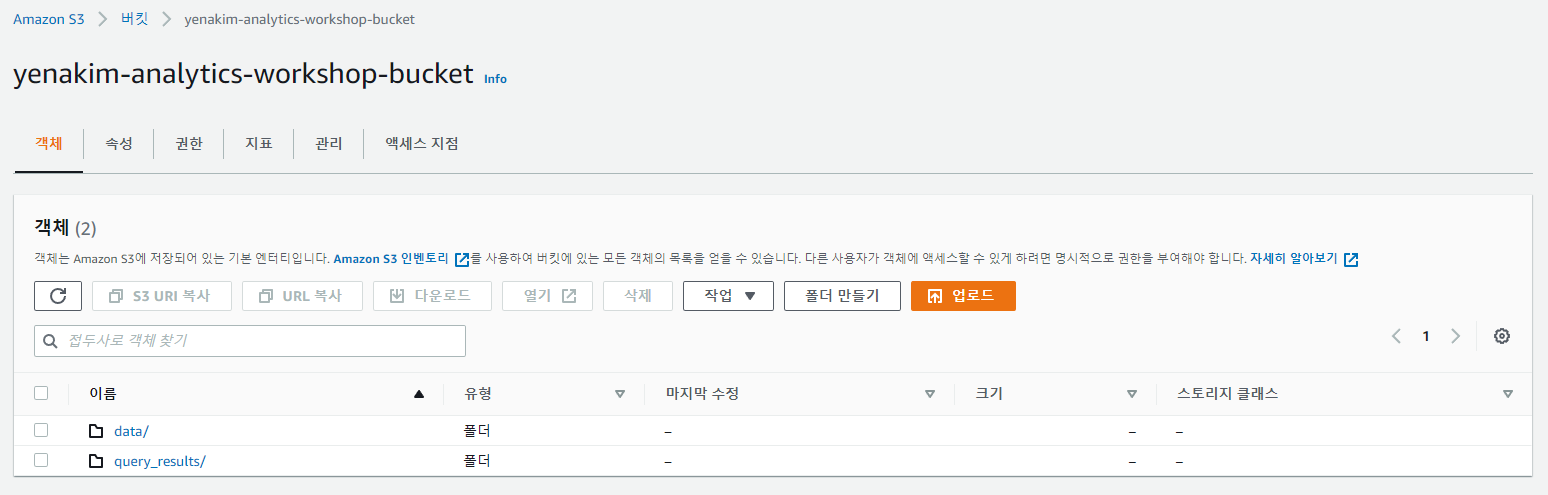
data로 들어갑니다.
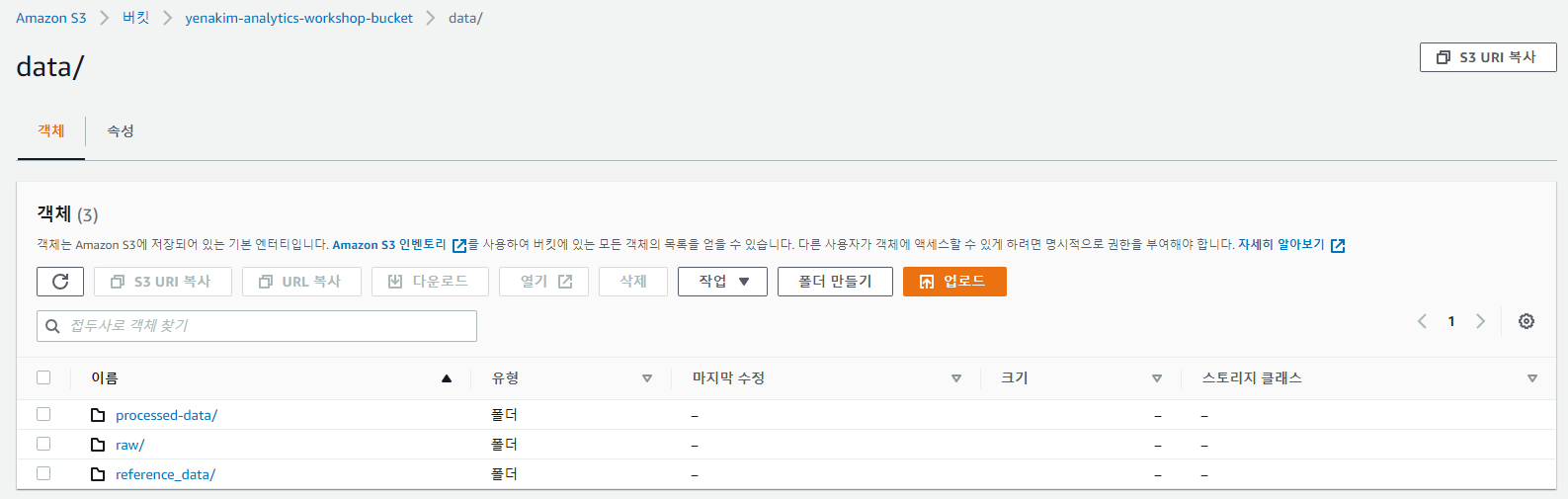
processed-data로 들어갑니다.
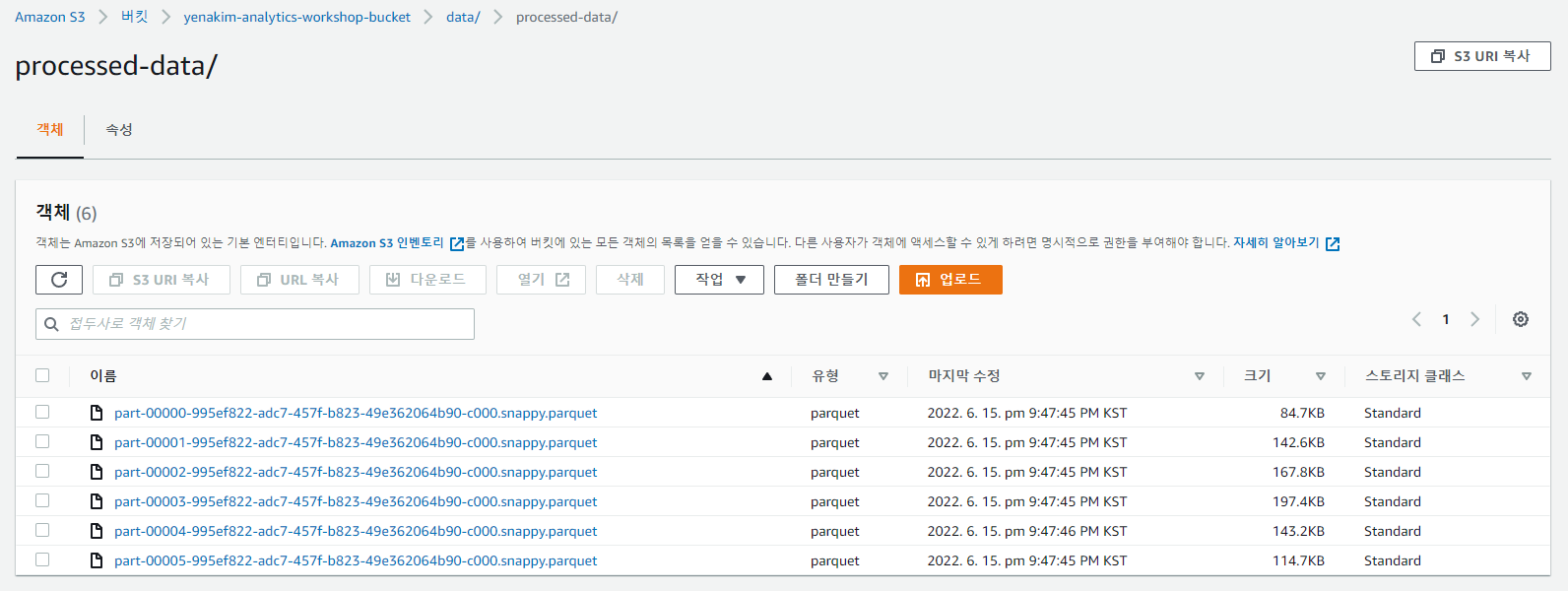
.parquet 파일들이 폴더에 잘 생성되었는지 확인합니다.
이제 데이터를 변환 했으므로 Amazon Athena를 사용하여 데이터를 쿼리할 수 있습니다. Glue 또는 Amazon EMR을 사용하여 데이터를 추가로 변환/집계 할 수도 있습니다.
EMR의 다음 모듈은 선택 사항입니다. 원하는 경우 건너 뛰고 Athena로 분석을 진행할 수 있습니다.