
이번 Catalog Data에서는 AWS Glue Data Catalog에 데이터 세트를 등록하여 Glue Crawlers의 도움으로 메타 데이터 캡처를 자동화 한다고 합니다. 카탈로그 엔터디가 생성되면 Amazon Athena에서 데이터의 raw 포맷의 데이터에 대해 쿼리를 시작할 수 있습니다.
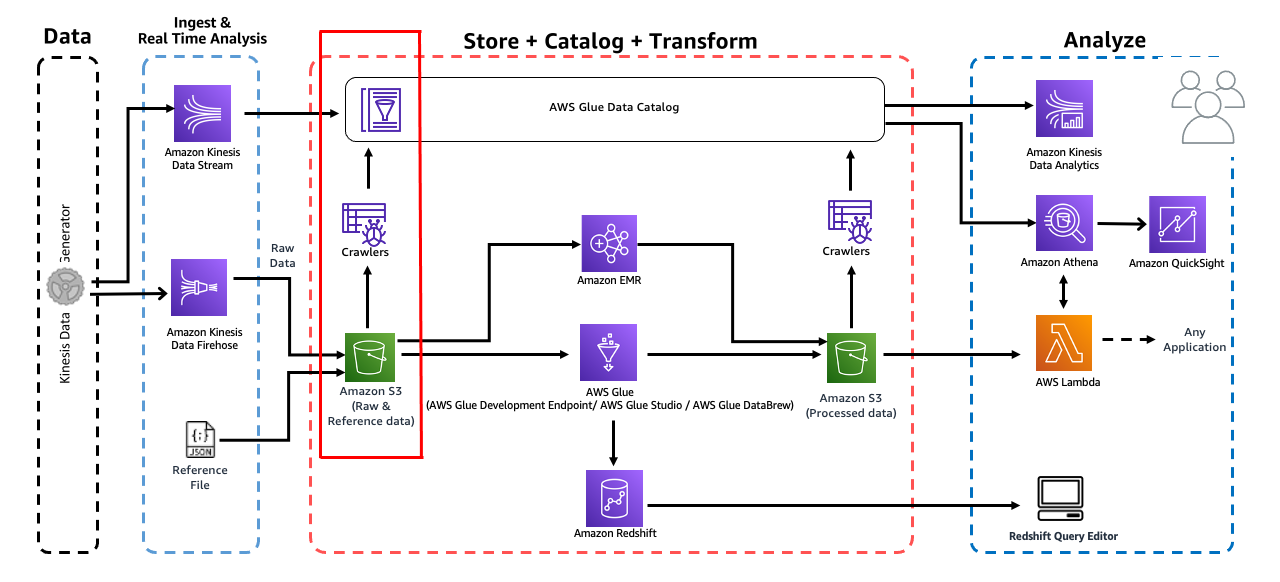
1. IAM Role 생성
IAM 콘솔 https://us-east-1.console.aws.amazon.com/iamv2/home#/roles로 이동하여 새 AWS Glue service role을 생성합시다.
역할 만들기를 클릭합니다.
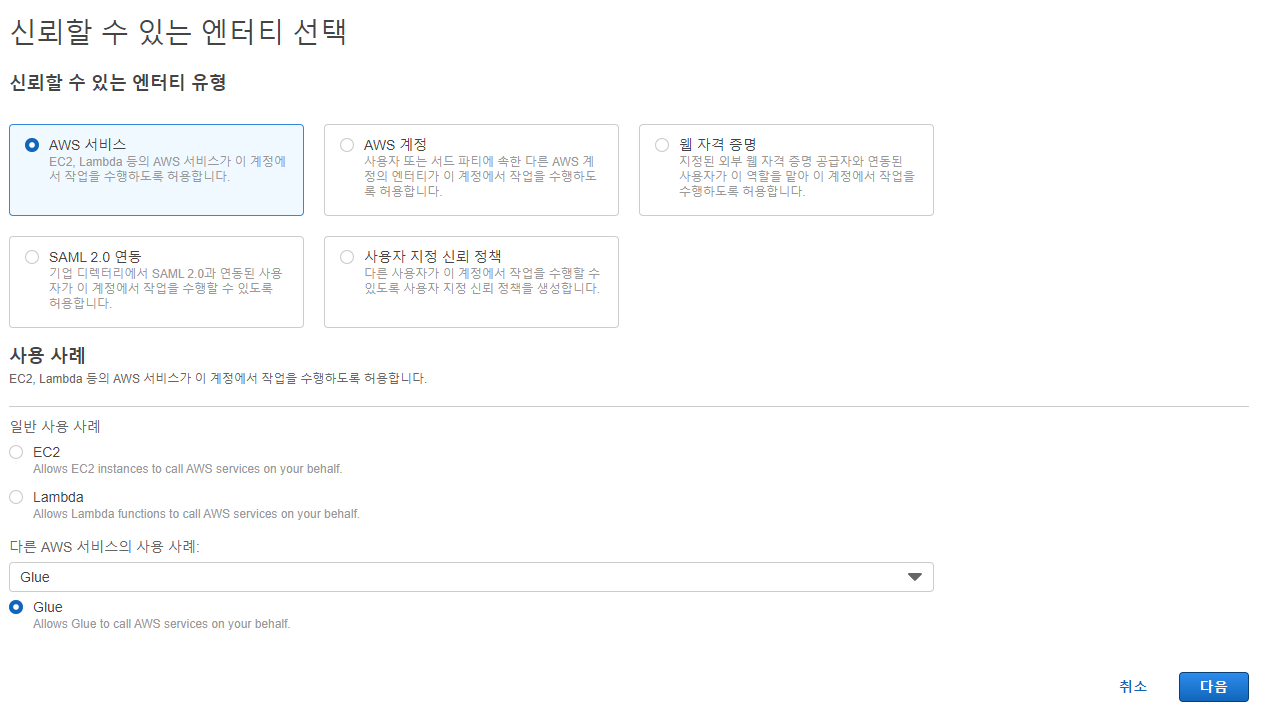
엔터티 유형은 AWS 서비스, 사용 사례는 Glue를 선택합니다. 다음을 누르면 권한 추가 창이 나옵니다.
AmazonS3FullAccess를 검색하고 체크박스를 선택합니다.
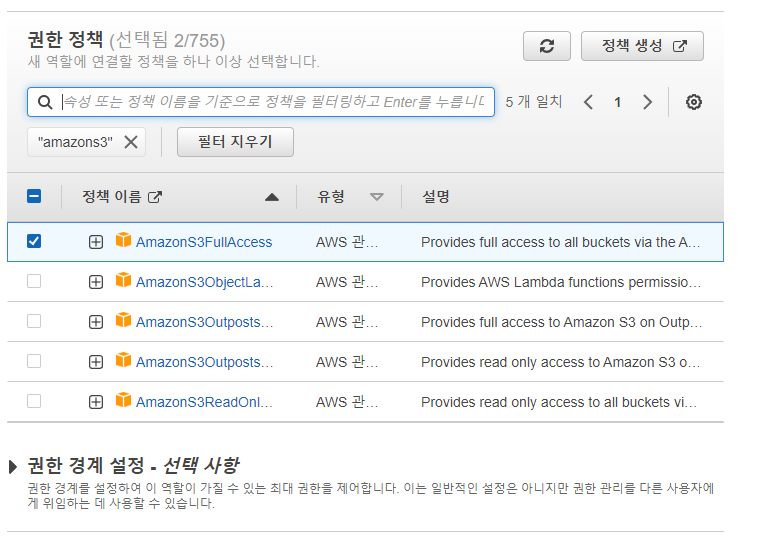
선택했다면 필터를 지워주고, AWSGlueServiceRole를 검색합니다. 필터가 그대로 남아있다면 검색이 되지 않으니 반드시 필터를 지워주세요.
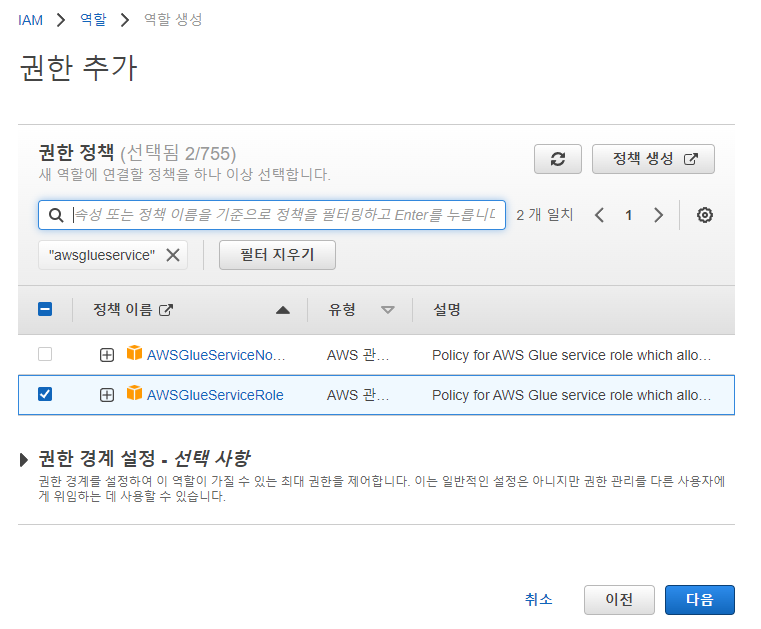
이제 다음을 누릅니다.
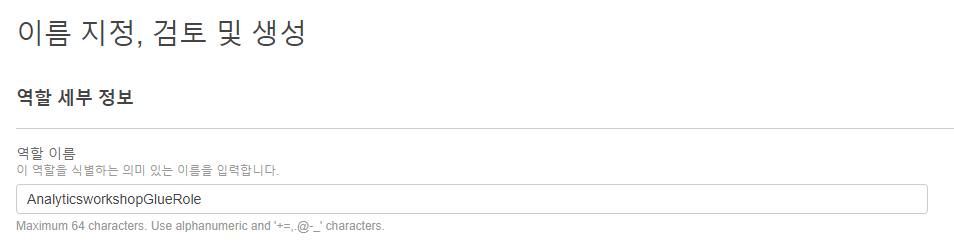
역할 이름은 AnalyticsworkshopGlueRole로 합니다.
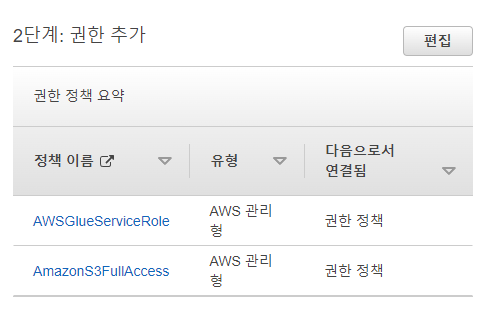
권한에 AWSGlueServiceRole과 AmazonS3FullAccess만이 있는지 확인합시다. 두 개만이 있다면 역할 생성을 누릅니다.
2. AWS Glue Crawlers 생성
AWS Glue 콘솔로 이동하여 Glue Crawlers를 생성하고 S3에서 새로 수집된 데잍의 스키마를 검색하는 단계입니다.
Glue 콘솔 https://us-east-1.console.aws.amazon.com/glue/home?region=us-east-1#/v2/home로 이동합니다.
왼쪽 패널에서 Crawlers를 클릭합니다.
크롤러 추가를 누릅니다.
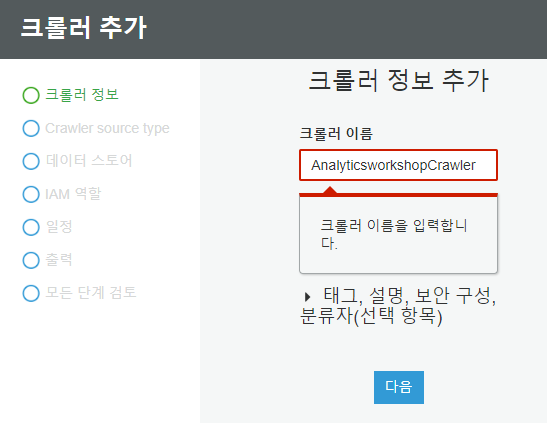
크롤러 정보를 누른 뒤 크롤러 이름에는 AnalyticsworkshopCrawler를 입력하고 다음을 누릅니다.
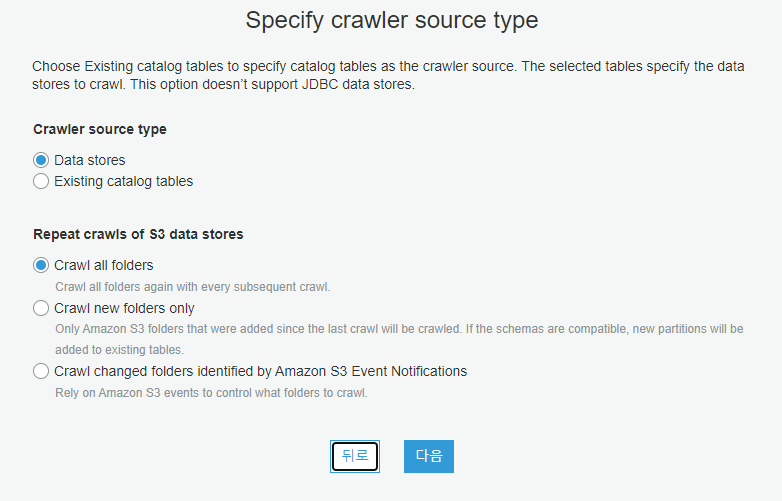
위와 똑같이 설정하고 다음을 누릅니다.
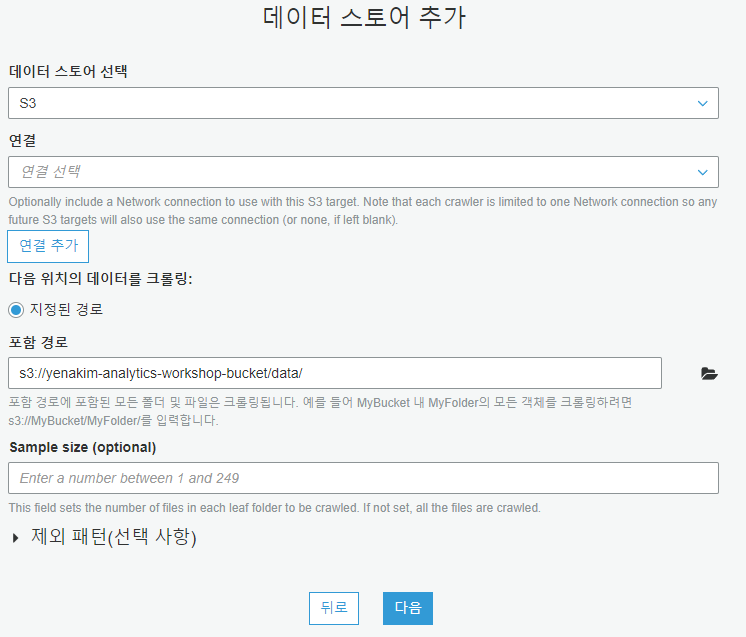
데이토 스토어는 S3, 다음 위치의 데이터를 크롤링은 내 계정의 지정된 경로, 포함 경로는 s3://yourname-analytics-workshop-bucket/data/로 설정하고 다음을 누릅니다.
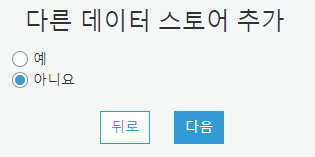
아니요를 선택합니다.
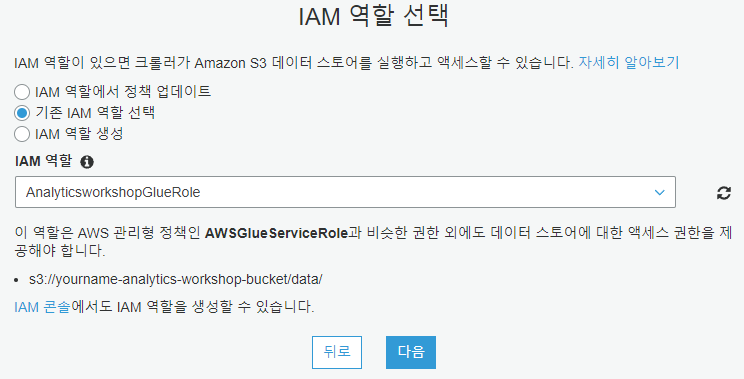
기존 IAM 역할 선택, Role 이름은 앞에서 만들었던 AnalyticsworkshopGlueRole을 선택합니다.
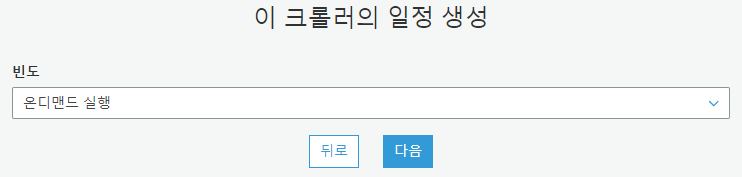
빈도는 온디맨드 실행으로 합니다.
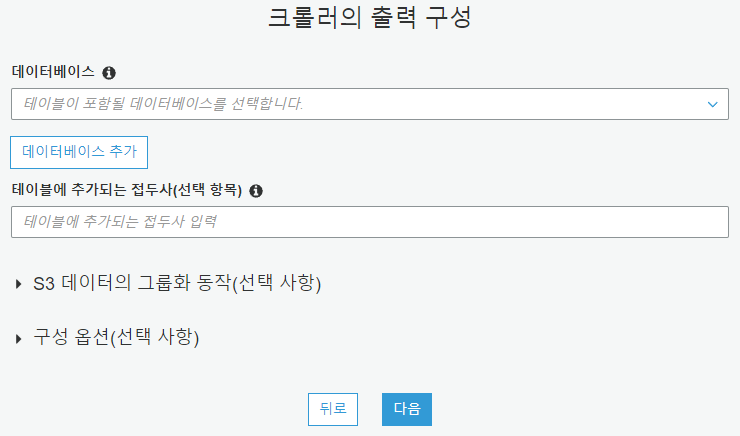
데이터베이스 추가를 누릅니다.
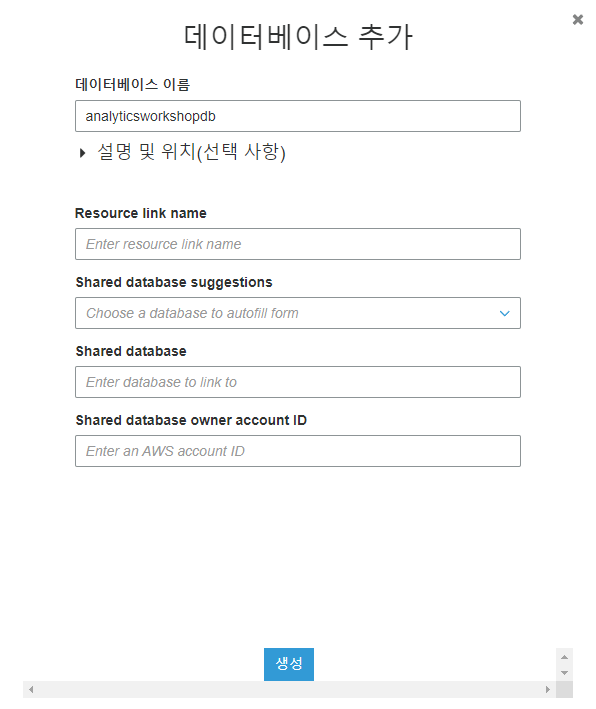
데이터베이스 이름은 analyticsworkshopdb로 하고 생성을 누릅니다.
다음을 누르면 단계별 구성을 확인할 수 있는데, 잘 검토하고 마침을 누릅니다.
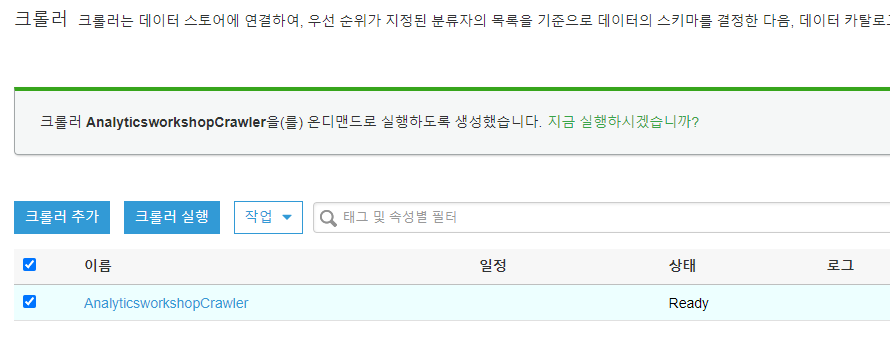
AnalyticsworkshopCrawler의 체크박스를 선택하고 크롤러 실행을 누릅니다. 실행되는 동안 잠시 기다립니다.
3. 카탈로그에서 새로 생성 된 테이블 확인
https://us-east-1.console.aws.amazon.com/glue/home?region=us-east-1#catalog:tab=databases로 이동하여 크롤링 된 데이터를 탐색합시다.
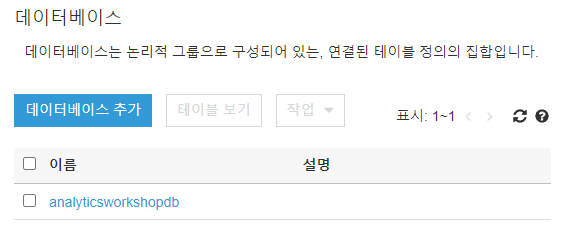
analyticsworkshopdb를 클릭합니다.

analyticsworkshopdb 내 테이블을 클릭합니다.
raw에 들어가면 데이터세트의 스키마를 둘러볼 수 있습니다. averageRecordSize, recordCount, compressionType가 기록되어 있습니다.
4. Amazon Athena를 사용하여 수집 된 데이터 쿼리
https://us-east-1.console.aws.amazon.com/athena/home?region=us-east-1#/query-editor에 들어갑니다.
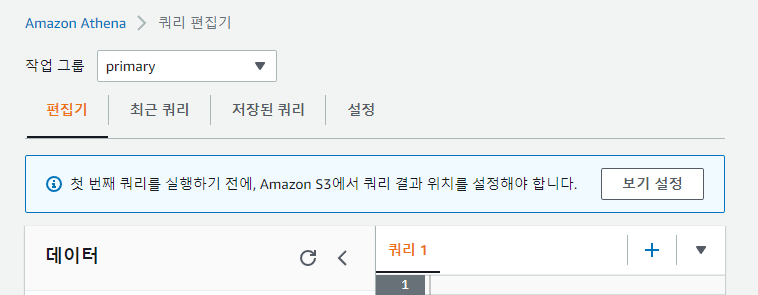
위 캡처본처럼 첫 번째 쿼리를 실행하기 전에, Amazon S3에서 쿼리 결과 위치를 설정해야 합니다.라는 경고창이 뜬다면 보기 설정을 누릅니다.
여기서는 관리를 누릅니다.
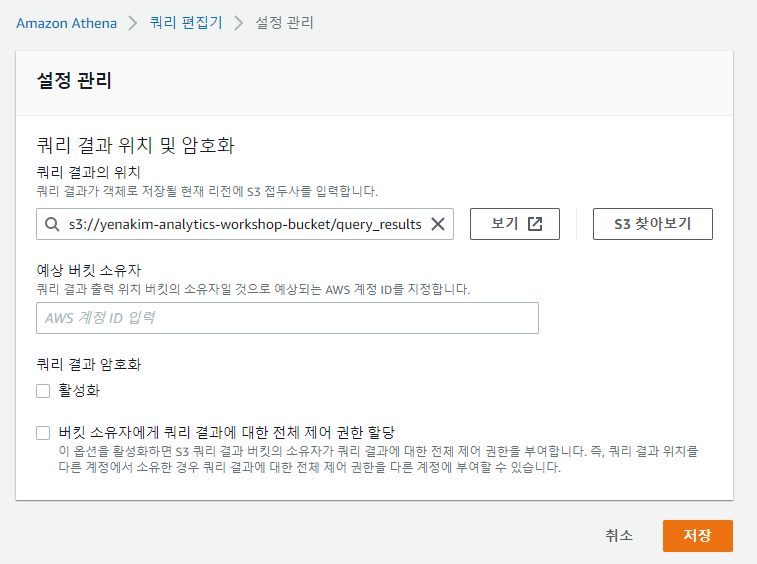
위처럼 쿼리 결과의 위치에 s3://yourname-analytics-workshop-bucket/query_results/를 입력하고 저장을 누릅니다.
문제를 해결했다면 다시 위의 링크로 들어가주고, 문제가 없다면 여기서부터 진행합니다.
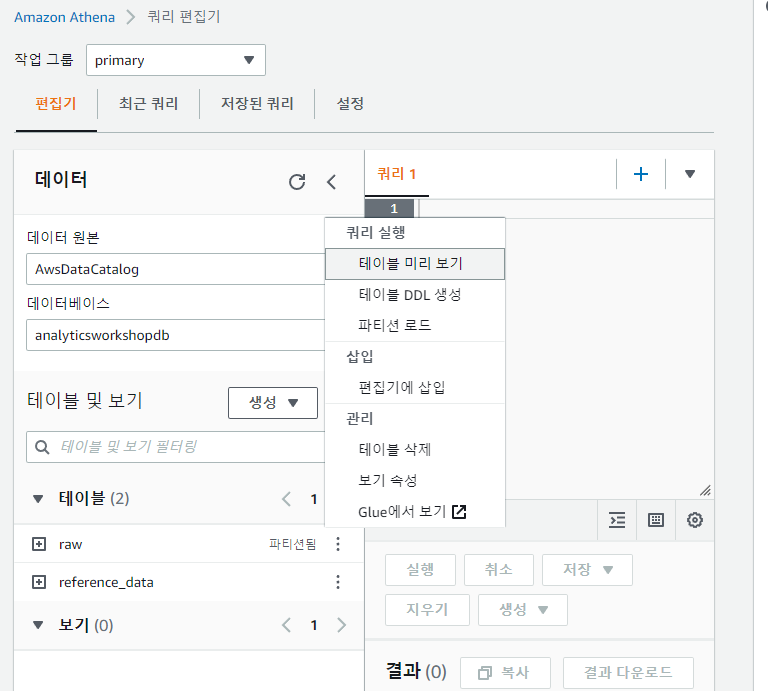
raw 옆에 점 세 개를 누르고 테이블 미리 보기를 눌러줍니다.
1
2
3
4
5
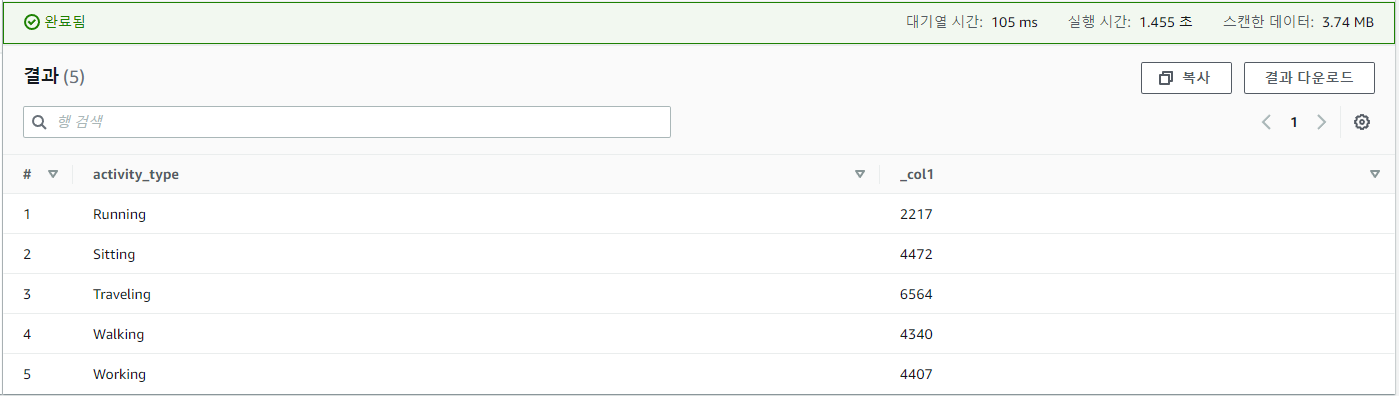
SELECT activity_type,
count(activity_type)
FROM raw
GROUP BY activity_type
ORDER BY activity_type
위 코드를 복사한 뒤 다른 쿼리 편집기에 붙여넣고 실행 버튼을 눌러줍니다. 아래 사진은 이미 실행한 상태라 다시 실행이라고 표시되어 있습니다.
카탈로그화된 결과는 다음과 같습니다.
이제 데이터를 카탈로그화 했으므로 다음에는 AWS Glue ETL을 사용하여 데이터를 변환합니다.