
이번 장에서는 저번 장에서 배운 개념을 실제 코드로 구현해 보는 것이 주 내용입니다. 합성곱 신경망을 구성하는 코드를 먼저 봅시다.
1. 합성곱 신경망 만들기
1
2
3
4
5
6
7
8
9
10
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input, train_target), (test_input, test_target) = \
keras.datasets.fashion_mnist.load_data()
train_scaled = train_input.reshape(-1, 28, 28, 1) / 255.0
train_scaled, val_scaled, train_target, val_target = train_test_split(
train_scaled, train_target, test_size=0.2, random_state=42)
우선 fashion mnist 데이터를 불러옵니다. 7장과 달라진 것은 데이터를 펼친 형태로 변형해 주는 것이 아닌 (28, 28)로 변형해 주는데, 이때 흑백 이미지기 때문에 깊이가 없지만 반드시 깊이가 있는 형태로 모델에 넣어줘야 하므로 (-1, 28, 28, 1)으로 reshape합니다.
1
model = keras.Sequential()
모델 객체를 만들었으니 차례로 층을 추가해주겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
model.add(keras.layers.Conv2D(32, kernel_size=3, activation='relu',
padding='same', input_shape=(28,28,1)))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Conv2D(64, kernel_size=(3,3), activation='relu',
padding='same'))
model.add(keras.layers.MaxPooling2D(2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
32개의 3 x 3 커널을 가진 합성곱 층, 2 x 2 커널의 Max 풀링 층, 그 다음엔 다시 64개의 3 x 3 커널을 가진 합성곱 층, 그 다음엔 2 x 2 커널의 풀링 층이 추가되어 있습니다. 결과를 내기 위한 밀집층 전에는 픽셀들을 펼치는 Flatten 층을 추가해주고, 밀집층들 사이에 Dropout 층을 넣어 과대적합을 방지해 줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
model.summary()
=>Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 32) 320
max_pooling2d (MaxPooling2D (None, 14, 14, 32) 0
)
conv2d_1 (Conv2D) (None, 14, 14, 64) 18496
max_pooling2d_1 (MaxPooling (None, 7, 7, 64) 0
2D)
flatten (Flatten) (None, 3136) 0
dense (Dense) (None, 100) 313700
dropout (Dropout) (None, 100) 0
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 333,526
Trainable params: 333,526
Non-trainable params: 0
_________________________________________________________________
summary 메서드로 모델의 형태를 살펴보면 위와 같습니다. 이 외에도 다음과 같은 방법으로 모델을 시각화할 수 있습니다.
1
keras.utils.plot_model(model)
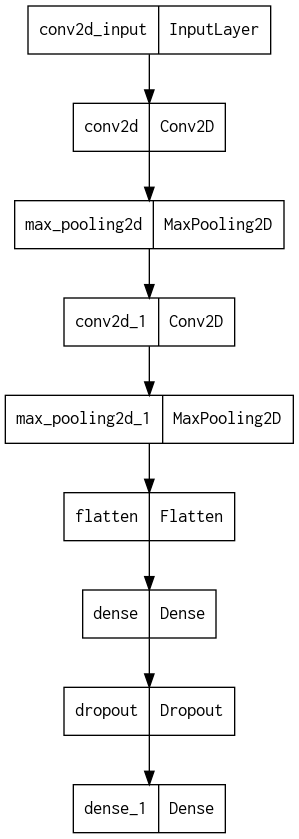
기능은 이것 뿐이 아닙니다. show_shapes로 input과 output의 크기를 알 수 있고, to_file로 파일을 저장할 수 있으며, dpi로 해상도를 바꿀 수 있습니다.
1
keras.utils.plot_model(model, show_shapes=True, to_file='cnn-architecture.png', dpi=300)
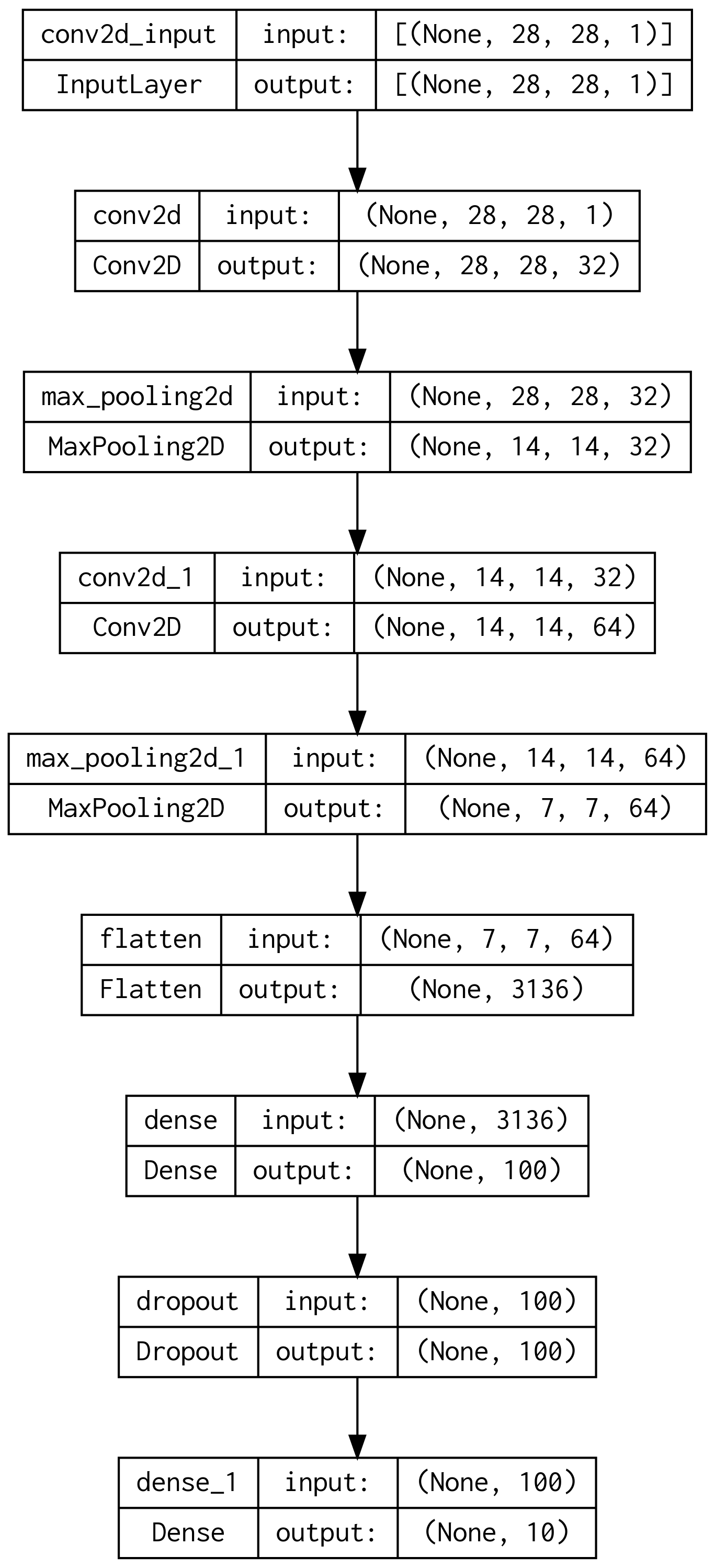
2. 모델 컴파일과 훈련
모델의 컴파일 과정은 7장에서 배웠던 것과 동일하며, checkpoint와 early_stopping 콜백을 이용하여 모델을 조기 종료하도록 합시다.
1
2
3
4
5
6
7
8
9
10
11
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',
metrics='accuracy')
checkpoint_cb = keras.callbacks.ModelCheckpoint('best-cnn-model.h5',
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=2,
restore_best_weights=True)
history = model.fit(train_scaled, train_target, epochs=20,
validation_data=(val_scaled, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])
이제 history에 저장된 검증 세트와 훈련 세트의 손실 함수값을 그래프로 그려 확인해 봅시다.
1
2
3
4
5
6
7
8
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train', 'val'])
plt.show()
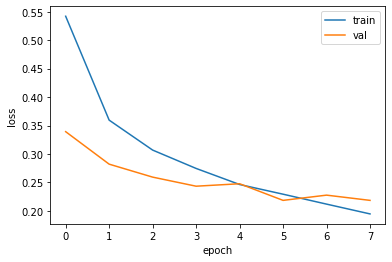
이 모델은 8번째에서 조기 종료 되었고, 6번째 에포크가 최적임을 알 수 있습니다.
1
2
3
model.evaluate(val_scaled, val_target)
=>375/375 [==============================] - 3s 8ms/step - loss: 0.2184 - accuracy: 0.9205
[0.21837739646434784, 0.9204999804496765]
evaluate 메서드로 모델의 손실함수 값과 정확도를 출력할 수 있습니다.
이제 데이터 셋 중 이미지 한 개를 뽑아 제대로 분류되었는지 확인해 봅시다.
1
2
plt.imshow(val_scaled[0].reshape(28, 28), cmap='gray_r')
plt.show()

0번째 이미지는 가방입니다.
1
2
3
4
5
preds = model.predict(val_scaled[0:1])
print(preds)
=>1/1 [==============================] - 0s 138ms/step
[[6.7846774e-12 8.1426743e-22 8.9696543e-16 7.7117090e-15 6.6757140e-14
1.4335832e-13 3.7601382e-14 3.6749163e-12 1.0000000e+00 1.8052020e-13]]
데이터 한 개만을 예측할 때는 데이터의 형태를 유지하기 위하여 슬라이싱합니다. 예측 결과를 출력해보면, 9번째 빼고는 거의 0에 가까운 결과임을 알 수 있습니다. 막대 그래프로 그려 확인해봅시다.
1
2
3
4
plt.bar(range(1, 11), preds[0])
plt.xlabel('class')
plt.ylabel('prob.')
plt.show()

앞에 나왔던 타깃값들을 보면 이것이 가방임을 쉽게 알 수 있지만, 타깃값들을 리스트로 만들어 예측값이 무엇을 출력하는지 봅시다.
1
2
3
4
5
6
7
classes = ['티셔츠', '바지', '스웨터', '드레스', '코트',
'샌달', '셔츠', '스니커즈', '가방', '앵클 부츠']
import numpy as np
print(classes[np.argmax(preds)])
=>가방
역시 가방이라는 결과를 얻었습니다.
1
2
3
4
5
test_scaled = test_input.reshape(-1, 28, 28, 1) / 255.0
model.evaluate(test_scaled, test_target)
=>313/313 [==============================] - 3s 9ms/step - loss: 0.2423 - accuracy: 0.9156
[0.24227263033390045, 0.9156000018119812]
마지막으로 test 세트를 evaluate 메서드에 넣어 이 모델의 성능을 평가합니다. 이 모델의 성능은 7장에서 밀집층으로 만들었던 모델보다 훨씬 좋다는 것을 알 수 있습니다.