
본격적으로 수학적인 이야기를 하기에 앞서, 혼공머신러닝 책을 통해 공부하면서 궁금했던 점을 이번 기회에 해결하게 되었기에 가볍게 언급하고 넘어가볼까 합니다. 그럼, 이야기를 시작해 보겠습니다.
1. 선형이란?
선형 회귀와 다항 회귀를 공부하면서, E(y) = ax² + bx + c와 같은 식이 어떻게 선형으로 불릴 수 있는지에 관해 의문이 들었습니다. 책에는 x²을 다른 변수, 예를 들어 z로 치환하면 선형 식이 되지 않겠느냐고 쓰여 있었지만, x²은 x에 종속된 변수인데 멋대로 독립변수로 만들어도 되는 것인지 의문이 들었습니다.
저는 이 문제에 관한 답을 3년 전 학교에서 배웠던 전산통계학 자료에서 찾았습니다. 수학에서 선형을 이야기할 때 변수 x에 관해 선형인지를 따지는데, 회귀분석에서는 그렇지 않습니다. E(y) = ax + b라면 모수 a, b에 관해 선형이기 때문에 선형인 것이고, E(y) = ax² + bx + c이더라도 x²에 관해서는 비선형이지만 모수 a, b, c에 관해 선형이므로 선형이라 부르는 것입니다. 이렇게 생각하니 말끔하게 이해가 되었습니다.
2. 선형 회귀
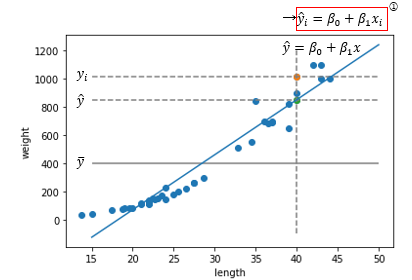
선형 회귀의 가장 기본적인 형태는 위와 같은 회귀선을 갖는 직선형의 모델로, 훈련을 통해 두 모수를 찾아내고 이 직선에 예측하고자 하는 데이터의 x값을 넣어 추정값을 도출합니다. 그렇다면, 무슨 기준으로 가장 적합한 모수들을 찾아내는 걸까요?
아, 그 얘기를 하기 전에 위에 빨간색으로 네모가 쳐져 있는 수식을 봅시다. 값 위에 모자(햇)이 씌워져 있는 변수는 회귀 곡선을 통해 추정한 값이라는 의미입니다. y의 추정값은 회귀 곡선 위에 있음이 자명하므로, 이 식은 성립합니다. 이후에도 이런 빨간 네모가 있는 수식들을 몇 개 더 보실 수 있을 텐데, 지금 당장 필요한 것은 아니고 이따 결정 계수 파트에서 사용할 수식들입니다.

우리가 선형식으로 타겟값을 추정하면, 추정값과 타겟값 사이에는 오차가 생깁니다. 이것을 잔차라고 부릅니다. 위의 식은 잔차의 정의로부터 온 것입니다. 아무튼, 추정값이 타겟값에 가까워질수록 모델의 성능이 뛰어난 것이니, 전체 타겟에서 이 잔차를 줄인다면 더 훌륭한 모델이라고 말할 수 있지 않을까요?
다만, 잔차는 타겟값이 추정값보다 작을 경우 음수가 될 수도 있습니다. 단순히 합해서 계산하는 것만으로는 더 좋은 모델을 만들 수가 없다는 것입니다. 이렇게 음수와 양수가 섞여 있을 때는, 일반적으로 제곱을 하거나 절댓값을 씌워 더하면 됩니다. 이제 잔차 제곱의 합을 최소로 하는 모수를 구해볼까요?

최소제곱법을 통해 모수를 계산하는 방법에는 여러가지가 있지만, 저는 각 모수에 관해 편미분하여 답을 찾기로 하였습니다. 다만, 공부하면서 의문이 들었던 것은 왜 각 모수에 관해 편미분해 0이 되게 만드는 값들이 잔차 제곱의 합을 최소로 만드느냐는 것입니다.
제가 맞게 생각했는지 확신할 수는 없지만, 저는 선형의 의미가 모수에 관해 선형이라는 말에 힌트를 얻어 두 모수를 독립변수로 하고 잔차제곱합을 종속변수로 하여 만든 함수를 그린 3차원 곡면을 상상해 보았습니다. 아마 이 방법이 옳게 되기 위해서는, 보자기 모양으로 마치 공의 아래쪽을 감싸고 있는 그런 곡면이 그려져야 할 것입니다. 이 곡면에서 각 축을 따라 편미분한 값이 0이 되는 지점은 일치하며, 공의 가장 아래 있는 점이고, 이 점은 명백히 잔차제곱합을 최소로 만들어줍니다.
왜 편미분해서 0이 되어야 하는지를 생각해 보았으니 이제 정말 편미분을 해봅시다.
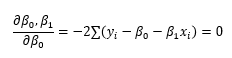
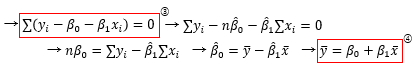
이 계산 과정에서는 중요한 식이 두 개나 도출됩니다. 3번 식은 모든 잔차의 합이 0이 된다는 것을 의미하며, 평균은 총합을 n으로 나누는 것이므로 잔차의 평균이 0이라는 뜻도 됩니다. 마지막에 도출된 식은 데이터의 평균이 회귀곡선을 지난다는 것을 의미합니다. 추후에 둘 다 써먹을 곳이 있으니 잘 기억해 둡시다.
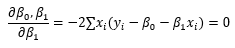
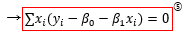
다른 모수 또한 위와 같이 편미분하여 값을 풀어낼 수 있지만, 이제 결정 계수때 사용할 식은 위의 것(5번)이 전부이니 유도 과정은 쓰지 않고 넘어가겠습니다.
3. 결정 계수
결정 계수는 회귀 모델을 평가하기 위한 수치로, 총 변동 중 회귀선에 의해 설명되는 변동의 비율을 나타낸 것입니다. 지금 당장은 이 설명이 와닿지 않을테니 결정계수가 어떻게 구성되어 있는지부터 알아봅시다.
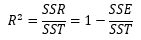
저는 SSE, SSR, SST를 설명하기 위해 가장 효과적인 방법은 그래프라고 생각합니다. 제가 그렇게 이해했기 때문이죠. 설명과 함께 그래프를 가져와 보겠습니다.
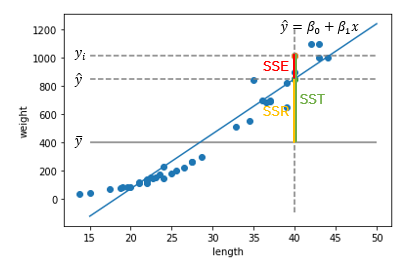

이 자료는 혼공머신러닝 3장 발표를 위해 만들었기에, 생선의 길이를 가지고 무게를 예측하는 문제 상황에서 설명드리겠습니다. 생선의 무게를 결정하는 요소는 무척 많고, 우리는 길이만을 가지고 생선의 무게를 설명하려 합니다. 그렇게 나온 값이 추정값입니다. 당연히 값을 완벽하게 예측하기는 어렵습니다. 길이만으로는 설명할 수 없는 무언가가 생선의 무게에 관여하고 있기 때문입니다. 즉, 길이로 설명되지 않는 무게의 변동, 이것이 우리가 모델을 만들 때 줄여야 하는 값이며, 아까까지 질리게 가지고 놀던 잔차제곱합입니다.
다음으로, SSR에 관해 알아보기 전에 먼저 SST를 살펴봅시다. SST에는 길이가 없을 때 무게의 총 변동입니다. 처음 이 정의를 봤을 때 왜 여기에 타겟값이 평균이 들어가는지 의문이 들었습니다. 그래서 다른 방식으로 이해하려고 고민하다보니, 실은 이 값이 어떤 표본공간에서 표본들의 평균을 빼고 제곱하여 모두 더한 값, 즉 무게의 분산이 됨을 알 수 있었습니다. 그러니 이 분산은 길이라는 독립변수 없이 온전히 무게 값만으로 알수 있는 무게의 분포인 것입니다. 이를 길이가 없을 때 무게의 총 변동이라고 무를 수 있다는 것에는 더 이견을 달 필요가 없었습니다.
마지막으로, SSR은 길이로 설명되는 무게의 변동입니다. 추정값으로부터 평균까지 얼마나 떨어져 있는지를 이야기하는데, 전체 변동으로부터 잔차를 제한 범위이니 길이로 설명되는 무게의 변동이라는 말은 제법 타당해 보입니다.
이 지점에서 고민을 한 번 했습니다. 길이로 설명되는 변동과 설명되지 않는 변동을 더하면 총 변동이 되는 건가? 제곱하지 않았을 때는 맞는 말이지만, 제곱하면 부수적인 항들이 나올텐데. 언뜻 이런 이야기를 강의에서 들었던 것 같아 자료를 뒤져보기 시작한 것도 이때부터였습니다. 그리고 다행스럽게도 원하는 자료를 곧 찾아낼 수 있었습니다.
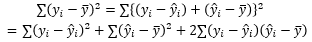
잔차 제곱의 내부에서 추정값을 더하고 빼는 약간의 스킬을 사용하면, SST = SSE + SSR이 성립되기 위해 무엇이 필요한지 알 수 있습니다.
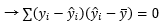
이제 이것을 증명하기 위해 아까 찾아둔 다섯 개의 식을 불러올 차례입니다.

5번에 관해 부연설명하자면, 잔차에는 몇 가지 성질이 있는데 그 중 하나가 잔차와 모든 다른 독립변수의 공분산은 0이라는 것입니다. Cov는 공분산으로 두 변수 사이의 선형 상관관계를 나타냅니다. Cov가 0이면 관계가 없고, 양수이면 양의 상관관계(기울기가 양수), 음수이면 음의 상관관계(기울기가 음수)를 갖습니다. 즉, 잔차는 모든 독립변수와 선형 상관관계가 없습니다. 이것을 유도하기 위해서 5번과 2번의 식이 필요한데, 적어둔 공분산 계산식에서 첫번째 항은 5번에 의해 0이 되고, 두번째 항은 2번에 의해 0이 됩니다.
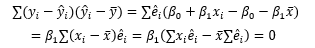
첫번째 등호에서는 1, 2, 4번을 사용하며, 두번째 등호는 그냥 값을 계산한 것이고, 세번째 등호는 2번과 5번을 사용합니다. 이제 SST = SSE + SSR이 성립한다는 점을 확실하게 확인했습니다. 다만, 이 경우는 특성이 1개인 무척 간단한 경우였기 때문에 특성이 늘어나거나 다항 회귀일 경우에는 어떤 방법을 거쳐 모수를 찾아내는지에 관해 기회가 된다면 다시 다루어보고 싶습니다.